Autores: Alexis Sebastian · Gabriel Ferreira · Pedro Pinheiro
Repositório: link
.png)
| Nome do Robô | 2Folds |
|---|---|
| Explicação Nome | 2Folds faz alusão ao conceito de “dobras” (folds) utilizado na validação de modelos de Machine Learning. A nomenclatura simboliza a dualidade estratégica do robô: o primeiro fold processa a estrutura técnica e quantitativa dos ativos , enquanto o segundo fold interpreta a entropia dos dados macroeconômicos e o fluxo de sentimento do mercado. |
| Hipótese da estratégia | Estratégia baseada na junção entre a técnica de modelagem preditiva usando Ensemble Learning e os sinais que vem da Análise de Sentimento adjuntos a dados macroeconômicos. Assim, criando um modelo “melhor e mais robusto” no lugar de implementar cada um separadamente |
| Tipo de Estratégia | Portfólio |
| Classe de Ativos | Ações |
| Universo | Ibovespa |
| Holding Period | Semanal |
| Qual Plataforma Testou a estratégia | Python |
| Benchmark Estratégia: | IBOV |
1. Introdução
A previsão do mercado de ações é um dos desafios mais complexos no campo da ciência de dados financeiros, dada a sua natureza não linear, não estacionária e altamente volátil. Fatores econômicos inter-relacionados, eventos políticos e o alto ruído do mercado contribuem para tal complexidade, tornando as metodologias tradicionais de previsão como a análise estatística, frequentemente não consigam atender as dependências complexas do mercado.
Dessa maneira, o presente projeto adota uma metodologia de modelagem multimodal, ponderando o poder do aprendizado de máquina de Ensemble com o apoio da Análise de sentimento de Mercado.
1.1 Abordagens Quantitativas e Comportamentais
1.1.1 Evolução da predição do mercado financeiro
Não é de hoje que vários bancos, gestoras e traders tentam aplicar métodos numéricos complexos para a predição do mercado de capitais. Historicamente, Wall Street em 1929 operava com os seus players, tendo como base demonstrativos financeiros das empresas (análise fundamentalista), mas principalmente tomando decisões com base na sua experiência empírica e intuição humana. O grande ponto de inflexão ocorreu a partir do final da década de 1970, consolidando-se em 1982, quando Jim Simons, um renomado doutor em matemática, fundou a Renaissance Technologies. Foi ali que ele provocou uma ruptura paradigmática no setor, aplicando meios puramente quantitativos como a estatística clássica e o cálculo estocástico. Utilizando ferramentas como regressões lineares multivariadas, Filtros de Kalman e modelos de suavização exponencial, a gestora buscou a predição desse mercado instável através da identificação de sinais matemáticos em vez de justificativas econômicas.
Entretanto, a contínua evolução computacional e o aumento exponencial no volume de dados expuseram as limitações intrínsecas desses métodos lineares diante da complexidade caótica dos dados atuais. A busca incessante por capturar padrões mais intrincados e não lineares levou, inicialmente, à exploração de arquiteturas de Redes Neurais Profundas (Deep Learning). Destaque-se o uso de Redes Recorrentes (RNNs) e as LSTMs (Long Short-Term Memory), adequadas para lidar com sequências temporais.
Logo, para a estratégia deste projeto, optamos por uma abordagem que equilibra robustez e eficiência: as técnicas de Aprendizado de Máquina de Ensemble. Estas são a base fundamental para a previsão proposta, dada a sua superioridade comprovada sobre métodos tradicionais de ML e sua eficiência frente ao Deep Learning em dados tabulares. Os modelos de ensemble alcançam maior acurácia e resiliência ao combinar as saídas de múltiplos learners (modelos base), reduzindo a variância (erro de sensibilidade) e melhorando substancialmente a generalização do modelo em dados não vistos.
Nesse contexto, definimos o Extreme Gradient Boosting (XGBoost) como o principal algoritmo de Ensemble para a análise de dados financeiros. O XGBoost, juntamente com o LightGBM e o Random Forest, é um método de ensemble baseado em árvores de decisão que demonstrou alta eficácia em capturar interações não lineares complexas e lidar com grandes conjuntos de features.
1.1.2 A Importância da Análise de Sentimento e fluxo macroeconômico
O mercado é fortemente influenciado por fatores psicológicos e comportamentais dos investidores, que se manifestam em informações não estruturadas, como notícias e mídias sociais. A Análise de sentimento é a técnica de processamento de linguagem natural (NLP) que transforma esse volume de dados não estruturados em pontuações quantificáveis, capturando o humor do mercado em tempo real. A integração de tal técnica alinhada ao fluxo macroeconômico constante, gera um espaço de decisão bom para a escolha do investimento.
1.2 Motivações
É fácil ver que tanto modelos que se baseiam estruturalmente em dados técnicos, análise de sentimento e macroeconômicos, têm um enorme sucesso no sentido de acurácia. Portanto, em um contexto onde esses modelos operam de forma alinhada e complementar, projeta-se uma performance preditiva superior à utilização isolada de qualquer um dos métodos, resultando em um sistema capaz de interpretar tanto a estrutura puramente ténica quanto o contexto informacional do mercado.
1.3 Hipótese de investimento
“A hipótese fundamental deste trabalho defende que a integração de algoritmos de Ensemble Learning com indicadores técnicos e de análise de sentimento adjuntos a macroeconômicos, quando submetidos a um mecanismo de ponderação estratégica, gera um alpha superior ao obtido pela utilização isolada destas técnicas”
2. Fundamentação Teórica
2.1 O Algoritmo de Ensemble
XGBoost
O XGBoost (eXtreme Gradient Boosting) é uma biblioteca de aprendizado de máquina famosa por sua velocidade e desempenho. Para entender por que ele é tão poderoso, precisamos primeiro entender os “blocos de construção” que ele utiliza
Tal modelo, é um algoritmo de ensemble (conjunto) baseado em árvores de decisão. Ele combina as previsões de vários modelos mais simples e “fracos” para criar um modelo final robusto e preciso. Em vez de tentar criar um único modelo complexo, são combinados vários modelos simples chamados de aprendizes fracos.
O XGBoost usa uma técnica de ensemble chamada Boosting. Diferente do Random Forest, que cria árvores independentes em paralelo, o Boosting cria árvores sequencialmente:
-
O modelo começa com uma previsão inicial (geralmente a média);
-
A primeira árvore é treinada para corrigir os erros (resíduos) da previsão inicial;
-
A segunda árvore é treinada para corrigir os erros da primeira, e assim por diante.
O resultado final é a soma das previsões de todas as árvores.
Otimização de Segunda Ordem
O que diferencia o XGBoost de outros algoritmos de Gradient Boosting é a maneira como ele otimiza a função de perda (erro). Enquanto algoritmos tradicionais usam apenas a primeira derivada (o gradiente) da função de perda para guiar o aprendizado, o XGBoost utiliza uma aproximação pela Série de Taylor de segunda ordem.
O algoritmo usa tanto a primeira derivada (gradiente) quanto a segunda derivada (hessiana) para encontrar a direção de descida do erro de forma mais rápida e precisa. O objetivo do XGBoost em cada passo é encontrar uma árvore f(x) que minimize a seguinte função:
Onde:
- é a função de perda: o erro entre o valor real e a previsão anterior com a nova árvore.
- é o termo de regularização que penaliza a complexidade do modelo (número de folhas e magnitude dos pesos), evitando o overfitting.
O XGBoost aproxima a função de perda L usando derivadas de segunda ordem. A fórmula simplificada que o algoritmo resolve é:
Aqui aparecem os dois protagonistas da otimização do XGBoost:
- Gi (Gradiente): A primeira derivada do erro. Indica a direção para onde devemos ir para reduzir o erro.
- Hi (Hessiana): A segunda derivada do erro. Indica a curvatura da função de erro. Permite o cálculo do peso w correto da próxima folha adicionada.
Regularização na Matemática
Diferente de outros algoritmos que adicionam regularização como um “extra”, o XGBoost a inclui na derivação matemática da estrutura da árvore:
Onde:
-
: Penaliza o número de folhas (). Se o ganho de adicionar uma nova folha for menor que , a árvore não cresce.
-
: Penaliza o peso das folhas (regularização ), evitando que as previsões finais sejam extremas demais.
2.2 Processamento de Linguagem Natural - FinBERT
a) Introdução: Modelo FinBERT
O FinBERT é um modelo de Processamento de Linguagem Natural pré-treinado, construído sobre a arquitetura do BERT (Bidirectional Encoder Representations from Transformers) do Google. Sua base consiste em múltiplas camadas de transformadores que geram uma representação vetorial hi para cada termo xi, considerando o contexto bidirecional: H=Transformer(X). O diferencial do FinBERT é que ele foi submetido a um processo de Domain Adaptation, sendo treinado especificamente em um grande banco de dados de textos financeiros corporativos, relatórios de analistas e transcrições de chamadas de resultados.
Enquanto o BERT tradicional entende a língua de forma geral, o FinBERT compreende os jargões do mundo financeiro.
b) Lógica de Funcionamento
O modelo baseia-se no conceito de transfer learning que pode ser adotado pelo seguimento de 3 principais etapas:
- i. Pré-treinamento: O modelo começa com o conhecimento base do BERT para entender a estrutura sintática da língua. Durante esta fase, utiliza-se a técnica de Masked Language Modeling (MLM), onde a função de perda minimiza o erro na predição de palavras omitidas:
- ii. Adaptação ao mercado financeiro: O modelo é re-treinado em um grande conjunto de dados financeiros. É aqui que ele aprende os jargões e as conotações específicas da área através da minimização da entropia no novo domínio.
- iii. Fine-Tuning: Para a tarefa específica de análise de sentimento, o modelo recebe uma camada final de classificação e é treinado para categorizar frases como positivas, negativas ou neutras. O objetivo nesta fase é ajustar os pesos θ para minimizar a função de perda da tarefa:
3. Mecanismo de Atenção e Classificação
A arquitetura utiliza o mecanismo de Self-Attention. Isso permite que o modelo entenda o contexto de cada palavra em relação a todas as outras na sentença através da operação de Produto Escalar Escalonado:
Ao final do processamento, o vetor de saída passa por uma função Softmax, que converte os resultados numéricos (logits zi) em probabilidades que somam 1:
Utilização no projeto
O modelo foi usado para classificar manchetes relacionadas ao mercado financeiro, atribuindo a cada uma delas uma pontuação baseada na classe de maior probabilidade prevista:
Assim, foi possível compreender se a empresa estava em boa ou má fase através do sentimento extraído das notícias.
Factsheet
- Filtro: 25% melhores ativos por P/PVA e ROE
- Filtro de liquidez: > 500k (21 dias)
- Modelo A × Modelo B do ativo filtrado
- Holding ou venda do ativo “
4. Modelagem
No contexto onde dependemos de fontes de dados primárias e de acesso público, é fácil ver que é mais coerente criar um modelo para cada papel do nosso universo de ativos, ao invés de criar um modelo geral com informações de todas as empresas para prever todos os ativos. A influência natural de setores diferentes, políticas internas e culturas diferentes nas empresas listadas, etc; geram mais ruído e complexidade ao modelo preditivo.
4.1 Definição do Universo de Ativos e filtros
Seja o universo de ativos sendo o Ibovespa (IBOV), entramos na etapa de filtragem inicial, então selecionamos os ativos que têm liquidez (21 dias) > 500.000, tal filtro serve para evitar riscos como slippage e spread Bid-Ask. Além da liquidez, foram aplicados também filtro de preço mínimo de negociação (penny stocks) de cada papel > 1 reais, dado que ativos com preço baixo, por exemplo em centavos - Sofrem de uma volatilidade alta artificial, e posteriormente podendo gerar muito ruído pro modelo.
Por fim, também é definido um filtro de valor do ativo, selecionando apenas os ativos no 25 percentil melhores de P/PVA e ROE, tal percentil foi escolhido como um padrão justo do mercado, dado que 75% seria enviado a ser muito amplo e 5% tornaria o modelo restrito a uma estratégia de valor. Um ativo candidato é um ativo que obedece a essas regras.
4.2 Definição do Universo de Ativos e filtros
Para cada ativo candidato no ano inicial do backtest, é criado um modelo A e um modelo B, com as features sendo tratadas automaticamente ao cenário de cada ativo. Exemplo:
Modelo WEG_A x Modelo WEG_B
4.3 Regras de Operação
Operamos todas as sextas feiras úteis, onde os ativos que passarem pelo filtro de valor daquele ano, filtro de liquidez, são submetidas ao algoritmo de decisão que recalcula semanalmente a confiabilidade de cada modelo para cada ativo e atribui maior peso de decisão ao modelo mais vitorioso para aquele papel específico, que também deve ter um valor precisão esperado de (threshold) > 0.5%.
Assim, montamos um portfólio onde a alocação do capital segue um modelo onde todos os ativos aprovados recebem a mesma fatia do capital, e que há uma simulação realista de custos de transação de 0.1% sobre o turnover.
5. Engenharia de Dados
5.1 Fonte de Dados
As principais fontes deste projeto foram a biblioteca do yfinance que disponibilizou dados históricos de ativos, índices e cotações, o Portal de Dados Aberto da CVM que forneceu as informações coerentes ao demonstrativos financeiros das empresas e BACEN para dados macroeconômicos e demais informações que foram derivadas das mesmas.
5.2 Dados
5.2.1 Features Modelo A (para cada ativo i)
I. Dados de Preço e Volume
- Preço de Abertura
- Preço de Fechamento
- Volume
- High
- Low
- Daily_Range
- Real_Body
- Upper_Shadow
- Lower_Shadow
- Log-Retorno t, t-1
- Janelas Deslizantes: 14, 16, 30, 60 dias
II. Indicadores Técnicos
- Média Móvel Simples: 7 e 21 dias
- Média Móvel Exponencial: 12 e 26 dias
- RSI (Relative Strength Index): 7 e 14 dias
- MACD (Moving Average Convergence Divergence): 12 e 26 dias
- Bandas de Bollinger: 21 dias
- ATR (Average True Range): 7 e 14 dias
- High-Low Spread
- SQZ (Squeeze Momentum)
- KDJ (Stochastic Oscillator)
- Alvo (target)
5.2.2 Features Modelo B (para cada ativo i)
- Score Semanal
- IPCA Mensal
- Meta Selic
- IBC-BR (Índice de Atividade Econômica do Banco Central)
- Taxa de câmbio USD/BRL
- S&P 500
- VIX Index (oficialmente CBOE Volatility Index)
- Treasury Yield 10Y
- Brent Oil Price
- Alvo → Retorno semanal
Todos os dados foram normalizados para o período semanal, e filtrados somente pelas sextas-feiras, a fim de evitar ruído dado que os dados de segunda não serviriam para prever a sexta, evitando redundâncias para os modelo.
5.3 Tratamento de Features
Para garantir a qualidade do conjunto de entrada, realizamos um processo sistemático de seleção e redução de features, onde o tratamento de cada Modelo do ativo i, é tratado com relação às suas vertentes próprias (features) dos seus dados históricos.
Para o Modelo A, aplicamos o Coeficiente de Correlação de Pearson para identificar variáveis explicativas altamente correlacionadas entre si. A alta correlação linear (multicolinearidade) aumenta a variância do modelo e gera ruído pro modelo. Dessa forma, atributos redundantes foram removidos para reduzir o ruído e mitigar o risco de overfitting. Adicionalmente, utilizamos filtros baseados em Informação Mútua (Mutual Information) e testes Qui-quadrado para avaliar a dependência não-linear entre cada feature e a variável-alvo. Isso permitiu manter apenas os atributos com maior ganho de informação para a predição e ganho de informação.
Para o Modelo B, aplicamos apenas o filtro de correlação de Pearson para remover redundâncias óbvias, mas mantivemos as features macroeconômicas/globais dos testes de relevância (como Qui-quadrado e Informação mútua). Essa decisão visa preservar variáveis de causalidade econômica conhecida (ex: correlação entre Brent e PETR4), priorizou-se a relevância econômica fundamental sobre a dependência estatística pura.
Logo, em dias ou épocas de feriados, a maior parte das bolsas no mundo não operam, assim tendo vários dados faltantes tanto no Modelo A que foi derivado do mercado nacional, quanto do Modelo B que tem os índices cotados globalmente, assim foi aplicado um intenso trabalho para corrigir essas inconsistências, principalmente alinhando as datas entre os dois modelos.
5.4 Treinamento e Otimização
Ambas as features A, B foram colhidas no período de 2019-04-09 a 2025-10-01, assim quando tratadas, escolheu-se uma divisão de 80/20 temporal.
-
80 % treino, para treinamento;
-
20% teste, Reservada para o backtest.
Durante a etapa de treinamento, foi aplicada a Otimização Bayesiana de hiperparâmetros utilizando o framework Optuna (no período de treino). O processo de busca utilizou uma validação interna, para maximizar a métrica de performance.
Assim, toda essa metodologia garante que os resultados apresentados no backtest refletem uma simulação realista, onde o modelo tomou decisões baseadas apenas em informações disponíveis até o momento da operação, mitigando riscos de Overfitting e LookAhead-Bias.
5.5 Ferramentas e Bibliotecas
Utilizamos a linguagem de programação orientada a objetos Python 3, e o seu compilador, e derivado disso, as seguintes bibliotecas e ferramentas:
Pandas: Estruturação, limpeza e manipulação de dados em DataFrames.
NumPy: Operações matemáticas vetorizadas e suporte ao processamento numérico.
Scikit-learn: Pré-processamento, seleção de features e construção de pipelines.
XGBoost: Algoritmo de gradient boosting otimizado para tarefas de regressão e classificação.
Hugging Face Transformers: Inferência e utilização de modelos avançados de linguagem.
FinBERT: Modelo especializado em textos financeiros para análise de sentimento.
BeautifulSoup: Extração de textos por meio de web scraping.
Requests: Requisições HTTP para coleta de dados de APIs e páginas externas. YFinance: Download automatizado de dados históricos do mercado (OHLCV). BACEN API: Obtenção de indicadores macroeconômicos oficiais.
Matplotlib: Visualização básica de séries temporais e gráficos analíticos. Seaborn: Visualizações estatísticas suplementares à análise exploratória. Joblib: Salvamento e carregamento eficiente de modelos treinados.
Jupyter Notebook: Ambiente para experimentação, documentação e execução interativa do projeto.
6. Backtest
6.1 Regras e parâmetros
- O backtest foi realizado no período de 2024-07-26 a 2025-09-19.
- O rebalanceamento é feito toda sexta-feira.
- Custo de transação de 10 bps.
- A cada rebalanceamento, os ativos passam pelo filtro de valor, preço e liquidez.
- Decisão de modelo baseada no histórico de acertos de cada modelo para cada ativo, individualmente.
- Decision threshold (valor esperado para a acurácia) para compra deve ser > 0,5.
- Se o modelo comprou novamente, o ativo é mantido em holding.
- O backtest implementou um rebalanceamento diferencial a fim de otimizar o turnover.
- Filtro de valor: 25º percentil dos melhores P/PVA e ROE.
6.2 Resultados
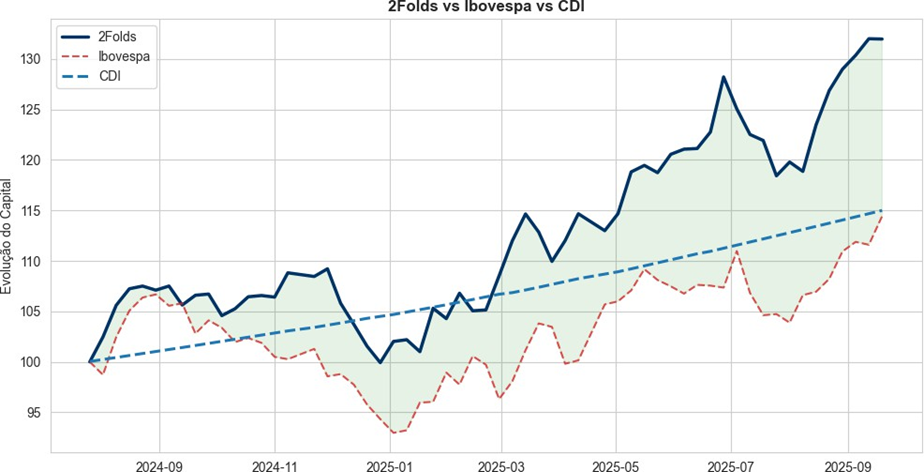
Info
Figura 1: 2Folds vs Ibovespa vs CDI
A estratégia demonstrou uma capacidade robusta de geração de alpha consistente, tendo como retorno líquido - Assumindo os custos de corretagem - de 31.96% em comparação a 14.41% do Ibovespa. Além de ter um sharpe ratio de 1.16 e com uma média de ativos semanais de 7.5 papéis (em holding e negociados). Além disso, observa-se que a estratégia apresentou desempenho superior ao ativo livre de risco, representado pelo CDI.
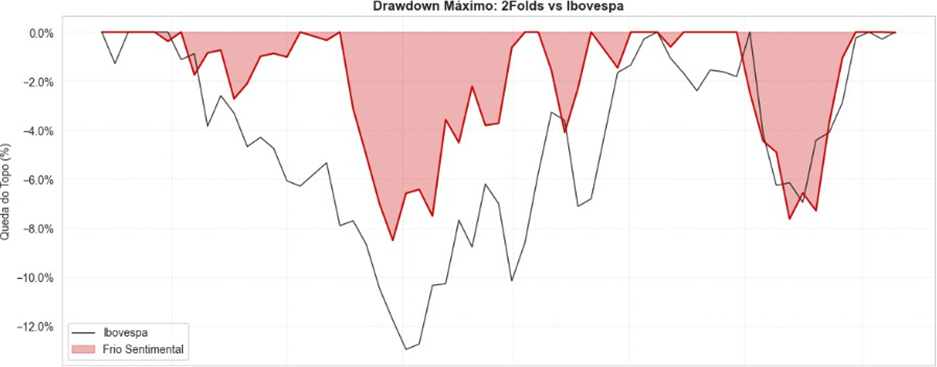
Info
Figura 2: Drawdown Máximo de 2Folds vs Ibovespa.
A resiliência do modelo é evidenciada pelo drawdown máximo controlado de -8.50%, significativamente inferior aos momentos de estresse observados no índice de referência. Isso valida a eficácia dos filtros de liquidez e fundamentalistas na proteção do capital durante correções de mercado.
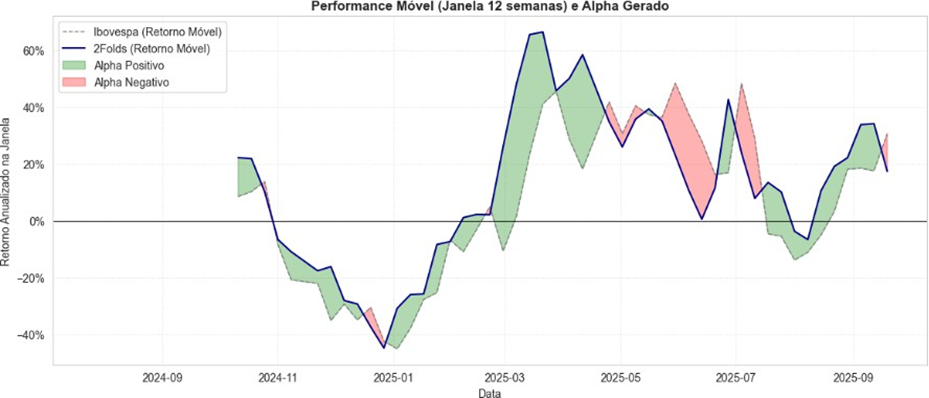
Info
Figura 3: Performance Móvel.
Mesmo nos períodos de quedas ( Novembro de 2024 - Fevereiro de 2025 e Agosto de 2025) é notável que o modelo ainda manteve um alpha em cima do benchmark.
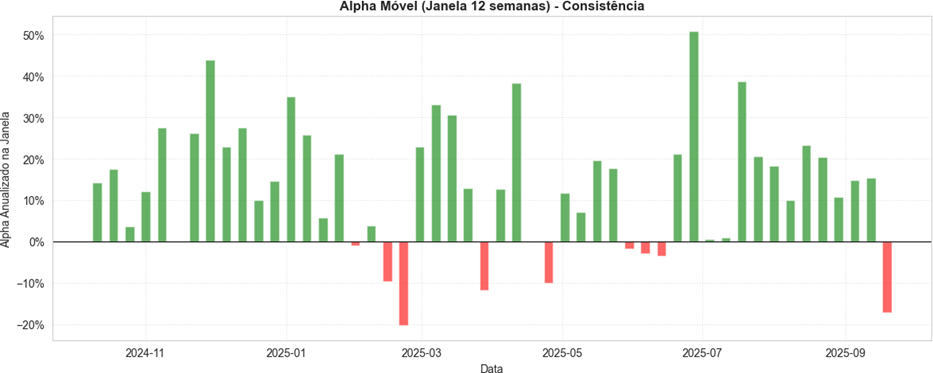
Info
Figura 4: Alpha Móvel.
A consistência da estratégia é observada através do Alpha Móvel (janela de 12 semanas), que se manteve positivo na maior parte do período. Com um Win Rate semanal de 57.63%, o modelo demonstra uma expectativa matemática positiva, lucrando através da consistência estatística e não de apostas esporádicas.
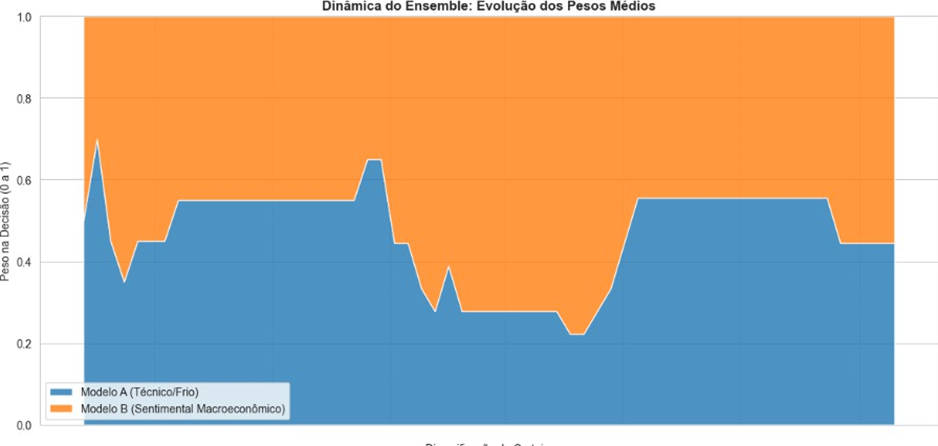
Info
Figura 5: Dinâmica do Ensemble.
A análise da dinâmica do ensemble confirma a adaptabilidade do algoritmo. Observa-se a flutuação dos pesos (wA e wB) ao longo do tempo, indicando que o algoritmo identificou corretamente quais momentos do mercado favoreciam o modelo A (técnico) e quais eram regidos pelo modelo B (Sentimental), ajustando a exposição automaticamente.
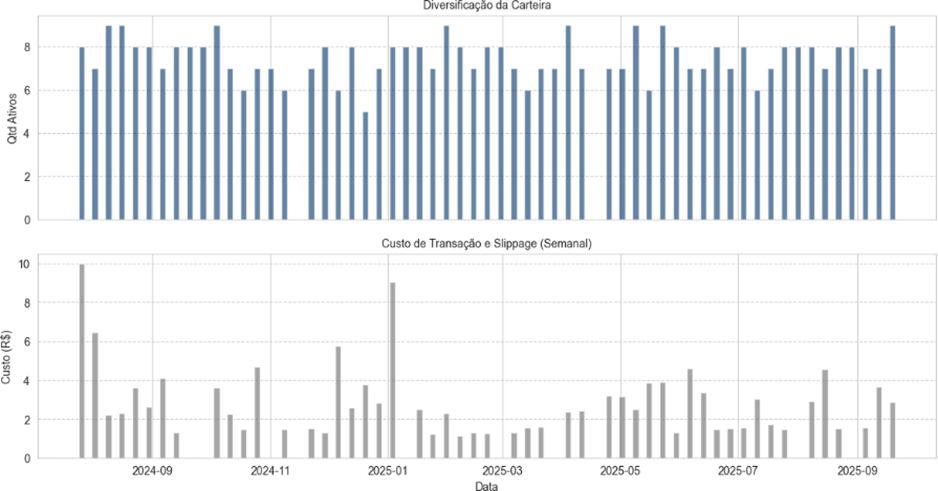
Info
Figura 6: Diversificação da Carteira e Custo de Transação e Slippage (semanal).
Segue ainda que a diversificação de portfólio se manteve alta desde o início do backtest, além do custo de transação ir diminuindo pelo fato da maior parte das boas ações foam identificadas pelo modelo e mantidas em holding por um bom período de tempo.
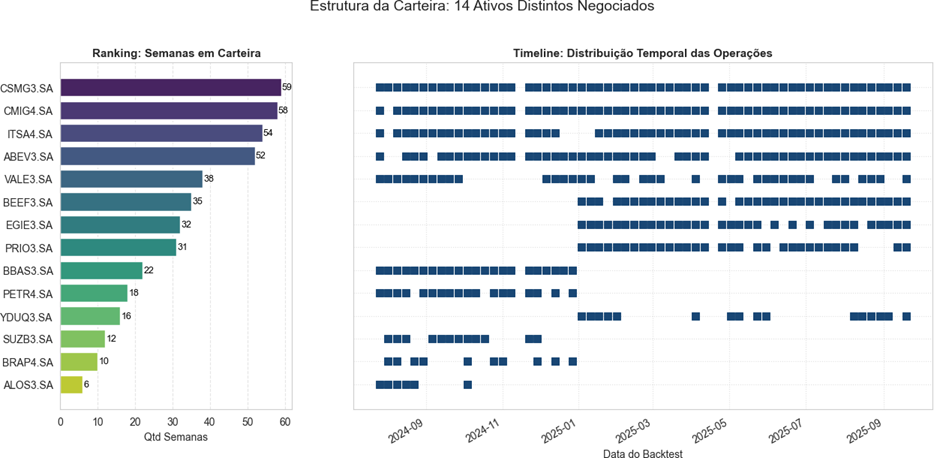
Info
Figura 7: Estrutura da Carteira.
A distribuição temporal das operações destaca uma característica do modelo de baixo turnover. Ativos como CSMG3 e CMIG4 permaneceram em carteira por 59 semanas, demonstrando que o modelo prioriza a captura de tendências longas, em detrimento de giros excessivos, o que reduz custos de transação.
Top 10 Ativos portfólio
| ATIVO | SETOR (B3) | SEMANAS | PRESENÇA % |
|---|---|---|---|
| CSMG3.SA | Utilidade Pública | 59 | 100.0% |
| CMIG4.SA | Utilidade Pública | 58 | 98.3% |
| ITSA4.SA | Financeiro | 54 | 91.5% |
| ABEV3.SA | Consumo não Cíclico | 52 | 88.1% |
| VALE3.SA | Materiais Básicos | 38 | 64.4% |
| BEEF3.SA | Consumo não Cíclico | 35 | 59.3% |
| EGIE3.SA | Utilidade Pública | 32 | 54.2% |
| PRIO3.SA | Petróleo, Gás e Biocombustíveis | 31 | 52.5% |
| BBAS3.SA | Financeiro | 22 | 37.3% |
| PETR4.SA | Petróleo, Gás e Biocombustíveis | 18 | 30.5% |
A composição atual do portfólio demonstra uma estratégia de alocação estruturada, com forte diversificação em setores defensivos e de capital intensivo, como Utilidade Pública e Financeiro. A seleção de ativos com alta consistência (acima de 90%), como CSMG3 e ITSA4, indica que o modelo prioriza resiliência e valor.
Essa estrutura obedece rigorosamente ao modelo ponderado e aos modelos A (técnico) e B (sentimento). Enquanto o modelo A garante a recorrência estatística semanal, o modelo B integra o viés econômico, captando índices globais e dados de sentimento que validam a exposição a commodities (VALE3, PETR4) e ao consumo (ABEV3) dentro do cenário macroeconômico atual.
Por fim, sabe-se que o modelo 2Folds, mas para validar a hipótese principal do projeto de unificar os dois tipos de modelo, o backtest foi aplicado unitariamente a cada um, tendo os seguintes resultados:
Modelo A
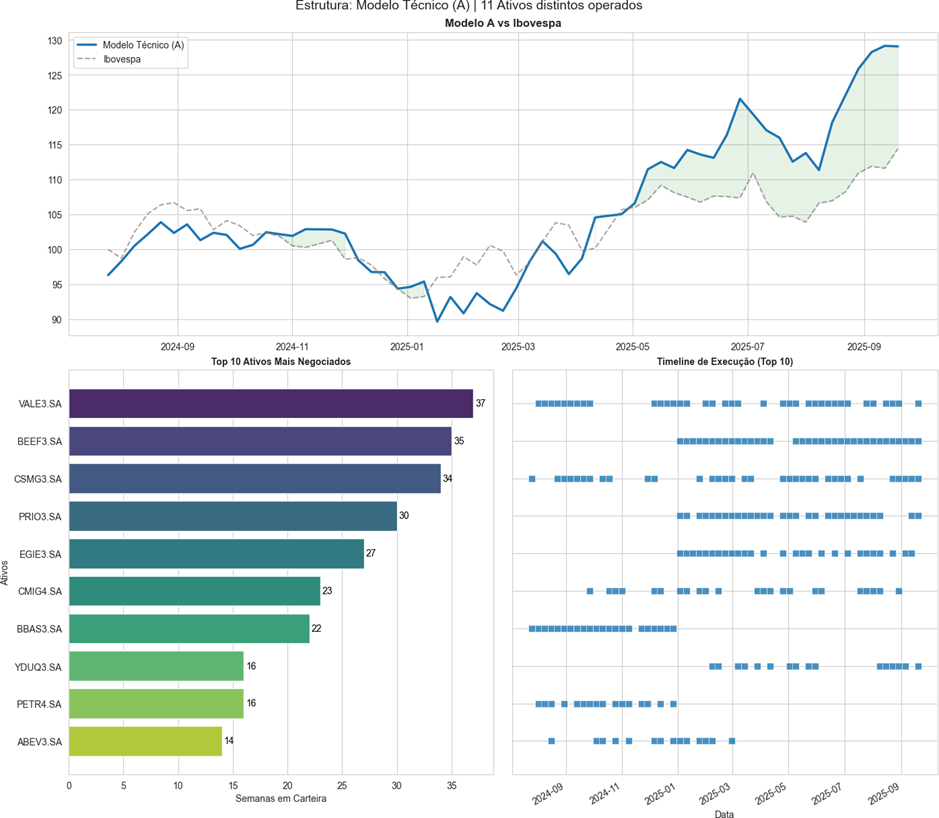
Info
Figura 8: Modelo A.
O modelo A teve um retorno líquido de 34.03% em comparação a 14.41% do Ibovespa. Além de ter um sharpe ratio de 1.01 e com uma média de ativos semanais de 4.8 papéis.
Modelo B
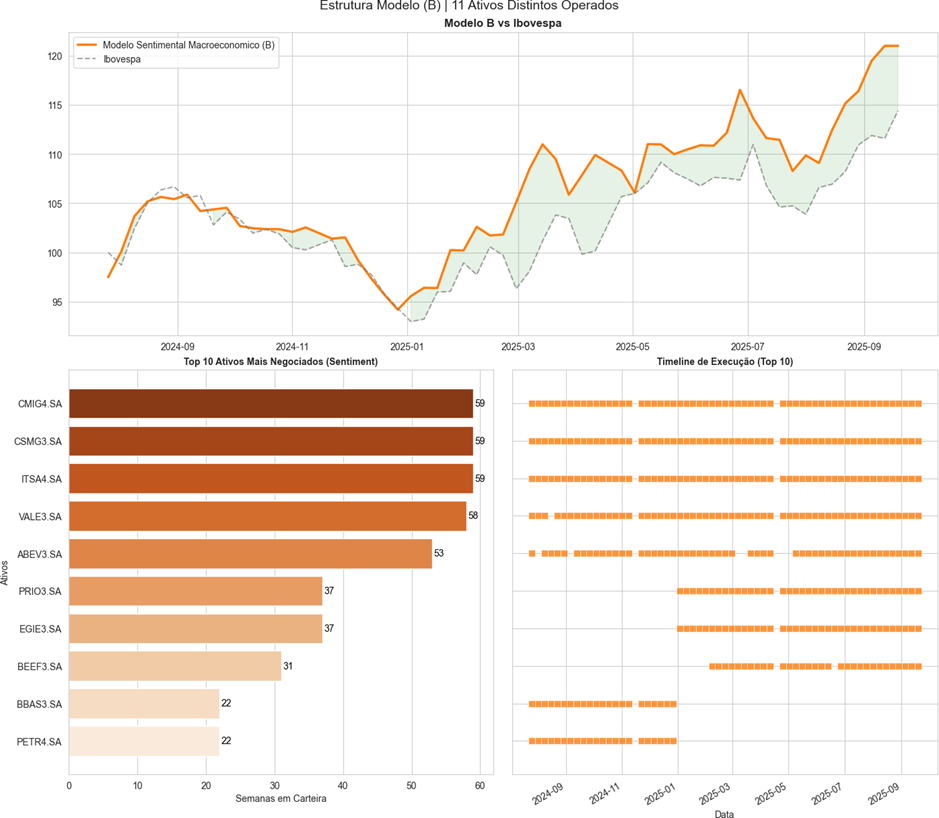
Info
Figura 9: Modelo B.
O modelo B teve um retorno líquido de +24.13% em comparação a 14.41% do Ibovespa. Além de ter um sharpe ratio de 0.78 Sortino Ratio de 0.20 e com uma média de ativos semanais de 8.3 papéis.
Dessa forma, o 2Folds através da rentabilidade e o sharpe ratio, superou tanto o modelo A quanto o modelo B quando aplicados unitariamente, vale ressaltar que a estratégia também tem uma defesa boa para períodos ruins captados pelo seu braço do fluxo macroeconômico/psicológico do mercado, reforçados pelo aprendizado oriundo do histórico técnico de tais ativos.
7. Conclusão
O presente trabalho assim, demonstra uma modelagem oriunda de uma fonte de dados consideravelmente simples em um mercado pequeno e volátil em comparação aos mercados de capitais globais, e mesmo assim, é fácil ver que o modelo sempre se destacou em relação ao benchmark e os modelos aplicados unitariamente, demonstrando a acurácia dos próprios aprendizado de máquina derivada dos modelos de Ensemble.
Sob a visão da metodologia aplicada, é fácil ver que a pesquisa valida a hipótese de que a integração multimodal — ao combinar a rigidez dos dados estruturados com a entropia informacional do processamento de linguagem natural e fluxo macroeconômica — confere uma vantagem competitiva superior à análise técnica tradicional. Dada a natureza comportamental do mercado brasileiro, nota-se que sua ineficiência não reside apenas na precificação dos ativos, mas na latência com que o “sentimento” é incorporado aos preços. Tal lacuna, assim, permite que o modelo híbrido arbitre sistematicamente essas distorções, provando-se uma ferramenta robusta para mitigar vieses onde a estatística pura, frequentemente, não consegue alcançar.
8. Limitação e Melhorias
Devido a dificuldade do Scrapping das notícias, a falta de dados de alguns tickets no período de treinamento e falta de quantidade do número de ações contidas nos dados da CVM de cada ação utilizadas para cálculo do filtro de valor, o backtest foi aplicado em um período curto de tempo.
Vale ressaltar também que, a viabilidade de dados deste projeto, foi limitado a ferramentas públicas e API’s. E também, é de suma importância destacar a importância do uso de IA no projeto, tanto para revisão da literatura financeira, quanto para evitar viés no código e sugestão de melhorias do projeto. Além do uso de modelos de caixa preta, que no caso do XGboost ainda é possível interpretar através de técnicas como SHAP, porém, reforçamos que tais modelos são poucamente usados em bancos e assets, devido a falta de interpretabilidade e controle deles.
Assim, alguns pontos de melhorias que podemos implementar para um projeto futuro os seguintes tópicos:
- Implementação de dados mais abrangentes para melhoria da acurácia do modelo e inclusão de dados exóticos, visando abordagens mais refinadas.
- Aumentar o período de treinamento para um intervalo maior e mais realista, incluindo períodos de queda (como o da Covid-19).
- Distinção de fontes de sentimento.
- Otimização avançada de portfólio.