Autores: Ana Beatriz Santos · Ana Beatriz Zaparoli · Julia Toledo · Luane Miranda
Mentor: Gabriel Navarro
Repositório: link
1. Introdução
A economia global atual é caracterizada por tantas incertezas políticas que a simples e tradicional poupança de recursos tornou-se insuficiente para a garantia e preservação real de patrimônio. Surge assim, como consequência, a necessidade de estratégias de investimento que equilibrem a busca por rentabilidade com a segurança da gestão de risco.
O processo de alocação da riqueza, a análise e o domínio do risco na gestão de investimentos são desafios permanentes para o meio acadêmico e para os administradores de ativos que atuam nos mercados financeiro e de capitais. Um dos primeiros acadêmicos a considerar a importância do risco na gestão de ativos foi Harry Markowitz, em artigo clássico, Portfolio Selection.
Nesse artigo, Markowitz percebeu que a diversificação é capaz de reduzir o risco específico de uma carteira. Com o passar das décadas, foram construídos modelos baseados na teoria de Harry, esses modelos tradicionais fundamentam-se frequentemente em premissas lineares e estáticas, que podem falhar em capturar a complexidade e a dinâmica dos mercados atuais.
Dessa maneira, para solucionar essas limitações, o avanço do poder computacional e a disponibilidade de dados permitiram a aplicação de técnicas de Inteligência Artificial nas finanças. Especificamente, o Aprendizado por Reforço (Reinforcement Learning) apresenta-se como uma abordagem promissora, permitindo o desenvolvimento de agentes autônomos capazes de aprender padrões não lineares e adaptar suas decisões de investimento em tempo real, visando superar as estratégias convencionais.
Nesse contexto, o presente trabalho propõe a implementação prática de um agente de Aprendizado por Reforço aplicado à gestão de portfólios compostos por ativos do índice S&P 100. O estudo visa confrontar o desempenho deste modelo dinâmico com estratégias de alocação consolidadas, especificamente a abordagem Ingênua (1/N) e a otimização de Mínima Variância de Markowitz, para verificar se a inteligência artificial é capaz de oferecer uma relação risco-retorno superior em períodos de teste desconhecidos pelo modelo.
A seguir, apresentaremos a fundamentação teórica, abordando desde os princípios da Teoria Moderna de Portfólio até os conceitos de Aprendizado por Reforço e o algoritmo PPO, a metodologia utilizada na coleta de dados e na configuração do ambiente de simulação, as estratégias de benchmark utilizadas para comparação e, por fim, discutiremos os resultados obtidos e a performance do agente inteligente frente aos modelos tradicionais, seguindo pelas conclusões.
2. Fundamentação Teórica
2.1 Teoria Moderna de Portfólio
A Teoria Moderna de Portfólio (MPT), introduzida por Harry Markowitz em seu renomado artigo “Portfolio Selection” (1952), revolucionou a gestão de investimentos ao deslocar o foco da análise individual de ativos para a análise do portfólio como um todo. O cerne da teoria reside na premissa de que o risco de um ativo não deve ser avaliado isoladamente, mas sim pelo impacto que sua inclusão causa no risco e no retorno global de uma carteira diversificada.
A MPT baseia-se no conceito de diversificação, demonstrando matematicamente que é possível reduzir a volatilidade total de um portfólio através da combinação de ativos que possuam correlações imperfeitas entre si. Em termos estatísticos, enquanto o retorno esperado de um portfólio é a média ponderada dos retornos dos ativos individuais, o risco (medido pelo desvio-padrão) é influenciado pela covariância entre os ativos.
Dois conceitos fundamentais da MPT são centrais para este projeto:
- Fronteira Eficiente: Representa o conjunto de portfólios que oferecem o maior retorno esperado para um determinado nível de risco, ou o menor risco para um determinado nível de retorno esperado. Investidores racionais buscam posicionar-se sobre essa curva.
- Portfólio de Mínima Variância (MVP): É o ponto na Fronteira Eficiente que apresenta o menor risco global possível. No contexto deste relatório, a estratégia de Mínima Variância (Seção 4.2) é utilizada como um benchmark de controle de risco, ignorando estimativas de retornos futuros para focar estritamente na estabilidade estatística baseada na matriz de covariância histórica.
A aplicação da MPT neste estudo serve como o contraponto clássico à abordagem de Aprendizado por Reforço, testando se a otimização baseada em parâmetros estatísticos estáticos ainda se sustenta frente a modelos adaptativos em cenários de alta volatilidade.
2.2 Aprendizado por Reforço (Reinforcement Learning)
O aprendizado por reforço (Reinforcement Learning - RL) é uma subárea de aprendizado de máquina (Machine Learning - ML) que, por meio de um processo de tentativa e erro na interação com um ambiente dinâmico, treina um agente para tomar decisões e, assim, alcançar os melhores resultados dentro de certo contexto.
Nesse cenário, o algoritmo de RL recebe um feedback a cada ação executada: se a ação for positiva, o agente ganha uma recompensa, caso contrário, recebe uma punição. Dessa forma, ele aprende uma política de atuação que maximiza a recompensa acumulada ao longo do tempo, ou seja, aprendem a tomar sempre as melhores decisões, mesmo que não pareçam vantajosas no curto prazo, podendo incluir algumas punições ou retrocessos ao longo do caminho. O RL é, portanto, um método poderoso para ajudar os sistemas de inteligência artificial (IA) a alcançar resultados ideais em ambientes não observados anteriormente, sendo eles complexos e incertos, como o mercado financeiro.
Para a formulação matemática deste problema, são definidos cinco componentes fundamentais:
- Agente: a entidade que toma as decisões (no caso deste estudo, o robô investidor).
- Ambiente: o meio onde o agente atua (o mercado de ações/S&P 100).
- Estado: a percepção atual do ambiente (ex: preços atuais e indicadores técnicos).
- Ação: o que o agente decide fazer (comprar, vender ou manter).
- Recompensa: o sinal numérico que indica o sucesso da ação (o lucro ou prejuízo obtido).
Para a operacionalização do agente inteligente, optou-se pela utilização do algoritmo Proximal Policy Optimization (PPO), implementado neste trabalho através da biblioteca Stable Baselines3. Desenvolvido pela OpenAI e conhecido por sua eficiência e facilidade de implementação, o PPO é especialmente adequado para problemas de controle contínuo e ambientes estocásticos de alta complexidade, como o mercado financeiro.
Diferentemente de métodos anteriores que sofriam com atualizações de política muito agressivas, o que poderia levar o agente a ‘desaprender’ estratégias úteis ou colapsar o treinamento, o PPO introduz um mecanismo matemático de ‘clipagem’ (clipping). A principal ideia por trás do PPO é atualizar a política de forma incremental, garantindo que as mudanças não sejam muito drásticas e que a política atualizada seja “próxima” da política anterior. Isso é feito através da definição de uma função de perda que mede a diferença entre a política atualizada e a política anterior. Na prática, isso garante um aprendizado mais seguro, consistente e monotônico.
Em suma, a escolha do PPO via Stable Baselines3 justifica-se pela necessidade de um algoritmo robusto, capaz de lidar com a natureza ruidosa e não estacionária dos dados financeiros sem comprometer a estabilidade do treinamento. Essa base teórica fornece o suporte necessário para a implementação prática do agente, cujos detalhes de arquitetura, pré-processamento de dados e definição do ambiente de simulação serão detalhados no capítulo de Metodologia a seguir.
2.3 Métricas de Avaliação de Desempenho
Para validar a eficácia do agente de Inteligência Artificial frente aos modelos tradicionais, a análise de rentabilidade isolada é insuficiente. É necessário avaliar o desempenho ajustado ao risco. Para isso, este estudo utiliza duas métricas: o Índice de Sharpe e o Maximum Drawdown.
2.3.1 Índice de Sharpe (Sharpe Ratio)
Desenvolvido por William F Sharpe, o Índice de Sharpe é projetado para ajudar os investidores a entender o retorno potencial de um investimento em comparação com seu risco. Quanto maior o Índice Sharpe, mais atraente é o retorno ajustado ao risco. Matematicamente, é definido pela equação:
Onde:
- Rp é o retorno médio do portfólio
- Rf é a taxa livre de risco (risk-free rate)
- σp é o desvio-padrão dos retornos do portfólio (volatilidade).
A partir do cálculo desse índice você consegue saber, na comparação entre dois fundos (no caso deste trabalho seriam estratégias, a com IA ou a de Markowitz), o quanto de retorno excedente que o fundo entrega para cada unidade de risco que toma, e qual das opções é a melhor.
2.3.2 Maximum Drawdown (MDD)
Enquanto o Índice de Sharpe mede a volatilidade média, o Maximum Drawdown (MDD) mede a maior perda histórica de um fundo ou ativo em um determinado período, ou seja, ele avalia o “pior cenário” vivido pela estratégia. Representa a maior queda percentual acumulada entre um topo histórico e o fundo subsequente antes que um novo topo seja atingido.
O MDD é crucial para a gestão de risco, pois mede a resiliência da estratégia e o “risco de ruína”. Em termos práticos, indica qual seria a perda máxima que um investidor teria sofrido se tivesse entrado no melhor momento e saído no pior momento dentro da janela de tempo analisada. Estratégias com MDD menor são consideradas mais seguras e consistentes, preservando melhor o patrimônio em momentos de crise.
3. Metodologia
A qualidade dos dados é um fator determinante para o sucesso de modelos de Aprendizado de Máquina. A seguir, apresentaremos o pipeline de engenharia de dados construído, desde a aquisição bruta até a transformação em vetores de estado (interpretáveis pelo agente inteligente).
3.1 Coleta e Tratamento de Dados
Como citado acima, o universo de investimento escolhido para o estudo foi o índice S&P 100, uma ETF (Exchange Traded Fund, em inglês, que pode ser traduzido livremente para fundo negociado em bolsa) que engloba as 100 maiores empresas de capital aberto dos Estados Unidos, garantindo alta liquidez e representatividade de mercado.
Para extrairmos a lista atualizada das ações presentes no S&P 100 fizemos web scraping da página oficial da Wikipedia, utilizando a biblioteca pandas para a estruturação. Com base nos tickers identificados, foram coletados os dados históricos de preços de fechamento ajustados diários.
Para garantir a integridade do backtest e mitigar ruídos, os dados brutos passaram por uma etapa rigorosa de limpeza, consolidada no arquivo matriz_final_v3_survivorship.csv. As principais etapas incluíram:
- Tratamento de Ações Gêmeas: identificou-se a presença de uma empresa com mais de uma ação listada (Alphabet Inc. com GOOG e GOOGL). Para evitar redundância e colinearidade perfeita,que prejudicariam o aprendizado da rede neural, realizou-se uma análise de correlação (que apontou ser maior que 0.99), optando-se pela remoção da classe de menor liquidez (GOOGL).
- Filtro de Histórico (Viés de Sobrevivência/Existência): ativos que não possuíam histórico completo durante a janela de treino (como empresas que realizaram IPO recentemente, ex: PLTR em 2020) tiveram suas janelas de tempo ajustadas. Isso evita que o modelo tente negociar ativos em datas onde eles ainda não existiam, garantindo a consistência da matriz temporal.
Migrando para a engenharia de atributos, o agente de RL não observa apenas o preço bruto, mas sim “derivadas” do comportamento do mercado que indicam tendências e riscos. Os dados foram processados para gerar um conjunto de indicadores técnicos (features), salvos no arquivo features_rl_sp100.csv. As variáveis de entrada fornecidas ao modelo incluem:
- Retornos Logarítmicos: variação percentual do ativo.
- Momentum: indicador de tendência de curto e médio prazo.
- Volatilidade Local (Rolling Sharpe): risco ajustado recente do ativo.
- Diferencial de Médias Móveis (mm_diff): distância do preço atual em relação à sua média histórica, indicando sobrecompra ou sobrevenda.
- Drawdown Recente (drawdown_63): percentual de queda em relação ao topo nos últimos 63 dias (aprox. um trimestre), alertando o agente sobre ativos em queda livre.
Por fim, foi aplicada a técnica de Normalização Z-Score em todas as features:
Este passo é crucial para redes neurais, pois coloca todas as variáveis na mesma escala, evitando que indicadores com valores absolutos maiores dominem o gradiente de aprendizado.
Vale lembrar que o conjunto de dados abrange o período de 01 de janeiro de 2020 a 31 de dezembro de 2025. Esta janela temporal foi selecionada estrategicamente para incluir diferentes regimes de mercado, como o crash provocado pela pandemia de COVID-19, o ciclo de alta inflacionária subsequente e a recuperação econômica recente. Expor o agente a estes cenários de alta volatilidade durante o treino aumenta a robustez do modelo.
Para fins de validação do modelo (Backtesting), os dados foram segregados cronologicamente para evitar o viés de antecipação (look-ahead bias):
- Conjunto de Treinamento (80%): período utilizado pelo algoritmo PPO para aprender a política de investimento (aprox. Jan/2020 a Dez/2024).
- Conjunto de Teste (20%): Período inédito, reservado exclusivamente para avaliar a performance do agente fora da amostra (Out-of-Sample), com início em 23 de dezembro de 2024.
3.2 Configuração do Ambiente de Treino
Para o treinamento do agente, foi desenvolvido um ambiente customizado denominado PortfolioEnv, compatível com a interface da biblioteca Gymnasium. Este ambiente modela o problema de alocação de ativos como um Processo de Decisão de Markov (MDP), onde o agente interage com o mercado passo a passo.
O ambiente foi configurado para fornecer ao agente uma visão completa dos indicadores técnicos processados:
- Espaço de Observação: a cada dia, o agente recebe um vetor contendo as features normalizadas (Retornos, Volatilidade, Momentum, Drawdown, etc.) de todos os 100 ativos do S&P 100.
- Espaço de Ação: o agente deve decidir a alocação de portfólio. A ação é contínua, consistindo em um vetor de pesos para os ativos. Para garantir que a soma dos pesos seja sempre igual a 1 (100% do capital alocado) e que não haja posições vendidas, aplicou-se a função de ativação Softmax na saída da rede neural:
Onde wi é o peso final do ativo i e ai é a ação bruta emitida pelo agente.
Além disso, também há a função de recompensa, que é o componente crítico que guia o aprendizado. Diferente de uma simples maximização de lucros, o ambiente foi programado para buscar um equilíbrio entre retorno e risco, penalizando também a movimentação excessiva da carteira (turnover) para dar um toque a mais de realidade, visto que há custos nessas movimentações, então queremos também minimizá-los. Conforme definido no código, a recompensa R_t no instante t é calculada por:
Onde:
- rp: retorno diário do portfólio obtido com os pesos escolhidos.
- σ²p: proxy de risco (neste estudo, calculado como o quadrado do retorno ou volatilidade instantânea), ponderado pelo fator de aversão ao risco λ = 0.5.
- Turnover: a soma absoluta das mudanças nos pesos de um dia para o outro
- c: custo de transação simulado (0.001 ou 0.1%), que incentiva o agente a evitar operações desnecessárias que corroeriam o capital.
3.3 Treinamento do Agente
O treinamento foi realizado utilizando o algoritmo PPO (Proximal Policy Optimization) da biblioteca Stable Baselines3. A arquitetura da política adotada foi a MlpPolicy (Multi-Layer Perceptron), uma rede neural profunda capaz de processar o vetor de estados e mapeá-lo para a distribuição de pesos ótima.
O processo de aprendizado ocorreu ao longo de 20.000 passos temporais (timesteps), permitindo que o agente vivenciasse múltiplos ciclos de mercado dentro do conjunto de treinamento (2020-2024). Durante essa fase, os parâmetros da rede neural foram ajustados iterativamente via gradiente ascendente para maximizar a recompensa acumulada definida na seção anterior. Após o término do treinamento, o modelo final foi salvo para ser submetido à fase de teste (backtest) com dados inéditos.
4. Estratégias de Benchmark (Comparação)
4.1 Estratégia Ingênua (1/N)
4.1.1 Introdução teórica da Estratégia 1/N
A estratégia 1/N, também conhecida como equal-weight, consiste em alocar o capital de forma igualmente distribuída entre todos os ativos disponíveis no portfólio em cada período de decisão. Em vez de utilizar informações sobre retornos esperados, volatilidades e correlações, essa abordagem adota uma regra simples e não paramétrica: cada ativo recebe o mesmo peso, independentemente de suas características individuais. Por essa razão, a estratégia 1/N é frequentemente classificada como um benchmark ingênuo, amplamente utilizado na literatura de finanças para fins comparativos.
No contexto deste projeto, a estratégia 1/N desempenha um papel central como baseline de desempenho para a avaliação das estratégias mais sofisticadas, como o portfólio ótimo de Markowitz e o modelo de alocação dinâmica baseado em aprendizado por reforço (Reinforcement Learning). Ao utilizar o 1/N como referência, é possível avaliar se os ganhos de complexidade, modelagem estatística e aprendizado adaptativo efetivamente se traduzem em melhorias econômicas mensuráveis, como maior retorno ajustado ao risco ou maior estabilidade ao longo do tempo.
A implementação da estratégia 1/N neste trabalho considera um ambiente empírico realista, no qual o conjunto de ativos disponíveis pode variar ao longo do tempo. Dessa forma, em cada período, o retorno do portfólio é calculado como a média transversal dos retornos dos ativos disponíveis naquele instante, ignorando ativos que não possuam observações válidas. Essa abordagem reflete uma situação prática de mercado, especialmente em bases ajustadas por sobrevivência, e evita a imposição artificial de que todos os ativos estejam presentes em todos os períodos da amostra.
Do ponto de vista metodológico, a escolha do 1/N como benchmark é particularmente relevante devido à sua robustez. Estudos clássicos da literatura, como DeMiguel, Garlappi e Uppal (2009), mostram que estratégias ingênuas de alocação frequentemente apresentam desempenho competitivo — e, em alguns casos, superior — quando comparadas a modelos de otimização sensíveis a erros de estimação. Isso ocorre porque o 1/N não depende da estimação de parâmetros como matriz de covariância ou retornos esperados, reduzindo significativamente o impacto do erro amostral.
Além disso, o uso da estratégia 1/N permite estabelecer um piso mínimo de desempenho para o projeto. Qualquer modelo proposto — seja baseado em otimização média-variância ou em aprendizado por reforço — deve, no mínimo, superar o desempenho do 1/N em termos de métricas de risco-retorno, como volatilidade, retorno acumulado e índice de Sharpe. Caso contrário, a adoção de modelos mais complexos não se justificaria do ponto de vista econômico.
4.1.2 Resultados obtidos com a Estratégia 1/N
A aplicação empírica da estratégia 1/N sobre a base de dados utilizada no projeto resultou em uma trajetória consistente de crescimento do portfólio ao longo do tempo, conforme evidenciado pelos resultados abaixo:
| Resultados obtidos com a Estratégia 1/N | |
|---|---|
| Retorno Anualizado | 18.82% |
| Volatilidade Anualizada | 16.66% |
| Sharpe Ratio | 1.13 |
| Máximo Drawdown | -15.56% |
O retorno acumulado, calculado a partir da média dos retornos dos ativos disponíveis em cada período, demonstra um desempenho que se reflete em um retorno anualizado positivo e economicamente relevante. Isso indica que, mesmo sem qualquer otimização explícita, a alocação equitativa entre ativos é capaz de gerar valorização ao longo do horizonte analisado, funcionando como uma referência sólida de desempenho.
Em termos de risco, a volatilidade anualizada observada reflete o caráter amplamente diversificado do portfólio, uma vez que o peso igualitário reduz a exposição excessiva a choques específicos de ativos individuais. Como consequência, o portfólio 1/N apresenta um perfil de risco mais estável quando comparado a carteiras concentradas ou altamente otimizadas, que tendem a amplificar a sensibilidade a erros de estimação ou eventos idiossincráticos.
O índice de Sharpe obtido a partir da estratégia 1/N indica um retorno ajustado ao risco competitivo, reforçando seu papel como benchmark eficiente. Mesmo sem recorrer a informações preditivas ou técnicas avançadas de alocação, o portfólio alcança uma relação risco-retorno consistente, servindo como um padrão mínimo de qualidade que qualquer modelo alternativo deve superar para ser considerado economicamente relevante no contexto do projeto.
Outro resultado relevante refere-se ao máximo drawdown, que captura a maior perda acumulada do portfólio a partir de um pico até um vale ao longo do período analisado. O valor observado evidencia a presença de períodos de retração, como é típico em séries financeiras, porém sem comprometer a viabilidade de longo prazo da estratégia, dado o posterior processo de recuperação refletido na trajetória do retorno acumulado. Essa métrica complementa a análise de risco ao oferecer uma visão clara da severidade das perdas potenciais enfrentadas pelo investidor.
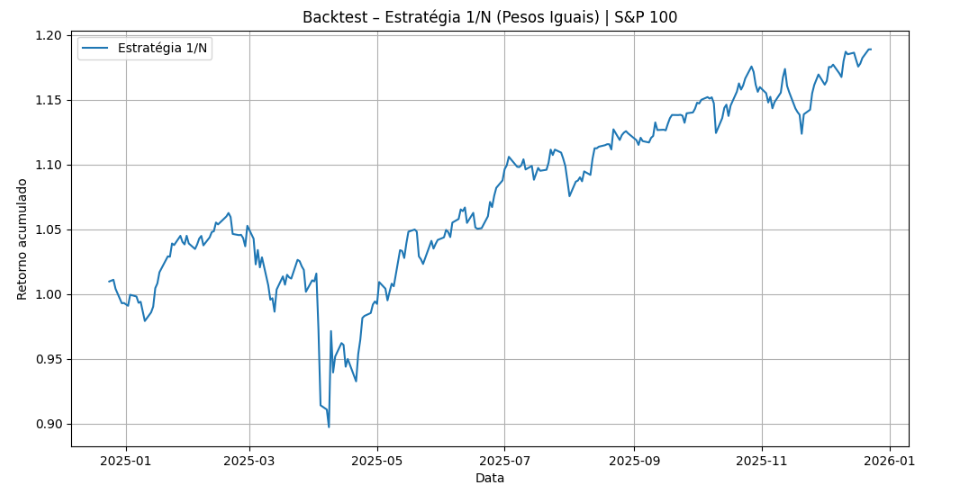
Além disso, também é pertinente mencionar a robustez da estratégia frente à variação no conjunto de ativos disponíveis ao longo do tempo. Ao calcular os retornos com base apenas nos ativos observáveis em cada período, a estratégia 1/N se adapta dinamicamente à estrutura da base, evitando distorções causadas por dados ausentes ou ativos recém-introduzidos. Essa característica torna os resultados particularmente realistas e alinhados com condições de mercado, reforçando a validade empírica do benchmark.
Em conjunto, os resultados de retorno anualizado, volatilidade, Sharpe Ratio e máximo drawdown confirmam que a estratégia 1/N apresenta um desempenho equilibrado, combinando crescimento de longo prazo com controle de risco, o que justifica plenamente sua utilização como benchmark central para a comparação com os modelos mais sofisticados desenvolvidos no projeto.
4.1.3 Importância dos resultados para o projeto
Os resultados obtidos com a estratégia 1/N estabelecem um ponto de referência essencial para a avaliação das estratégias mais avançadas propostas pelo grupo. Eles permitem verificar se modelos como Markowitz ou Reinforcement Learning efetivamente agregam valor econômico ou se seus ganhos aparentes decorrem apenas de maior complexidade computacional. Assim, o desempenho do 1/N funciona como um critério de validade empírica, ajudando a distinguir melhorias genuínas de possíveis efeitos de sobreajuste.
Além disso, os resultados do 1/N contribuem para a interpretação dos resultados globais do projeto, fornecendo uma base intuitiva para comparação e comunicação. Por ser uma estratégia simples, transparente e amplamente conhecida, seus resultados são facilmente compreendidos por leitores técnicos e não técnicos, fortalecendo a clareza e a credibilidade do estudo como um todo.
4.2 Estratégia de Mínima Variância (Markowitz)
4.2.1 Introdução teórica da Estratégia de Mínima Variância
A estratégia de Mínima Variância, derivada da Teoria Moderna de Portfólio de Harry Markowitz (1952), fundamenta-se na premissa de que a eficiência de um investimento não deve ser analisada pelo ativo individualmente, mas pela sua contribuição ao risco total de uma carteira. Diferente da estratégia ingênua 1/N, que distribui o capital independentemente das propriedades estatísticas dos ativos, o modelo de Markowitz utiliza informações de volatilidade e correlação para encontrar a combinação de pesos que minimiza a variância global do portfólio. No contexto deste trabalho, optou-se especificamente pelo Portfólio de Mínima Variância Global (GMV), que representa o ponto de menor risco na fronteira eficiente, independentemente das projeções de retornos esperados.
A implementação desta estratégia foi realizada através de um processo de otimização dinâmica com janela móvel (rolling window) de 63 dias úteis. A cada passo temporal, o modelo estima a matriz de covariância dos ativos do S&P 100 para capturar as dependências lineares entre eles. O objetivo matemático é resolver o seguinte problema de minimização:
Sujeito a Σ wi = 1 e wi ≥ 0.
Onde o Vetor de Pesos (wi, wj) representa as variáveis de decisão, a Variância da Carteira (σ²p) é a métrica de risco alvo e a Matriz de Covariância (S) captura a interdependência entre os retornos. O diferencial desta abordagem reside no aproveitamento do benefício da diversificação: ao identificar ativos com correlação baixa ou negativa, o modelo busca “anular” riscos específicos.
Para a execução do backtest, o modelo foi rebalanceado diariamente, deslocando a janela trimestral para capturar as mudanças recentes nas correlações do mercado antes de apresentar os resultados comparativos.
4.2.2 Resultados obtidos com a Estratégia de Mínima Variância (Markowitz)
Após a execução do backtest no período de teste (Dez/2024 a Dez/2025), a estratégia apresentou os seguintes indicadores e trajetória de retorno:
| Resultados obtidos com Markowitz | |
|---|---|
| Retorno Anualizado | 1.12% |
| Volatilidade Anualizada | 12.45% |
| Sharpe Ratio | -0.25 |
| Máximo Drawdown | -10.58% |
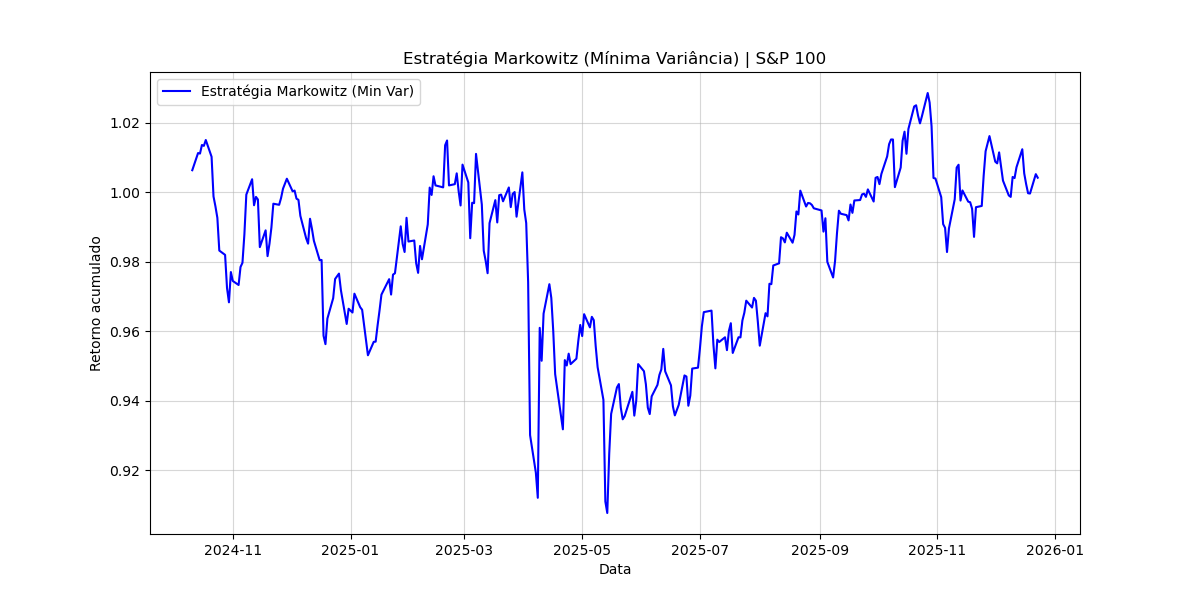 |
Ao observar os indicadores e o gráfico de desempenho, nota-se que a estratégia de Mínima Variância (GMV) entregou um Retorno Anualizado de 1.12%. Embora positivo, esse valor situa-se significativamente abaixo da estratégia 1/N apresentada anteriormente (18.82%), refletindo a natureza conservadora do modelo GMV, que prioriza a estabilidade em detrimento da busca por retornos elevados.
A Volatilidade Anualizada de 12.45% confirma que o modelo foi bem-sucedido em manter um perfil de risco mais baixo que o benchmark 1/N (16.66%). No entanto, essa proteção resultou em um Sharpe Ratio de -0.25. Matematicamente, o Sharpe negativo indica que a sofisticação da otimização não foi suficiente para gerar excesso de retorno sobre a taxa livre de risco no período.
Por fim, o Máximo Drawdown de -10.58% mensura a maior desvalorização do pico ao vale. Sob a ótica da gestão de risco, essa métrica é superior à da estratégia 1/N (-15.56%), evidenciando a capacidade de preservação de capital do modelo de Markowitz. O resultado demonstra que, embora o portfólio não esteja imune a estresses de mercado, ele reduz a amplitude das perdas em cenários de alta volatilidade sistêmica, cumprindo seu papel técnico de mitigação de risco.
4.2.3 Síntese Comparativa dos BenchMarks
Em suma, a comparação entre a estratégia 1/N e a Mínima Variância (Markowitz) revela o trade-off fundamental entre simplicidade e otimização estatística no contexto do S&P 100. Enquanto o portfólio de pesos iguais demonstrou uma performance superior em termos de retorno absoluto e eficiência (Sharpe de 1.13), beneficiando-se da robustez contra erros de estimação, o modelo de Markowitz provou sua eficácia técnica no controle rigoroso de risco. Com uma volatilidade de 12.45% e um drawdown mais contido (-10.58%), o modelo otimizado cumpriu seu papel de proteção patrimonial, ainda que a compressão dos retornos tenha limitado sua competitividade econômica no período de 2025.
5. Resultados e Discussão
5.1 Performance no Período de Teste
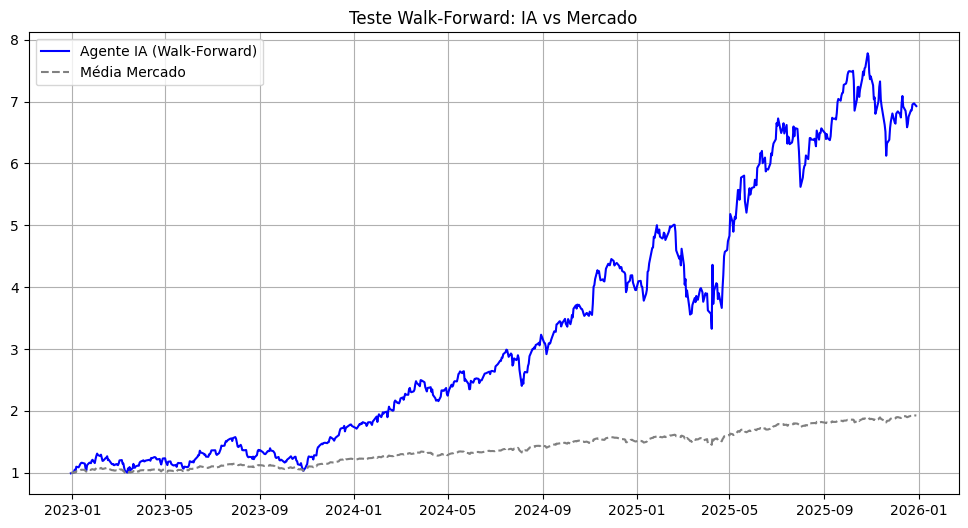
Para execução do backtest, foram escolhidas as metodologias de Walk-Forward e Permutação. Os resultados do teste walk-forward são representados pela curva de capital acumulado abaixo, concatenando resultados out-of-sample, ou seja, momentos onde o modelo tomou uma decisão sem acesso a dados futuros.
5.2 Tabela de Métricas
Os resultados obtidos pelo modelo de aprendizado por reforço denotam uma relação mais acentuada de risco-retorno. Comparando a estratégia com os benchmarks, o agente apresenta uma maior Sharpe Ratio, mas sua perda máxima e volatilidade indica que é uma estratégia arriscada para investidores conservadores e aversos à perda. Um ponto que cabe destacar é o contraste entre o retorno anualizado e a volatilidade anualizada quando comparado às estratégias naive e de Markowitz. Apesar de ser uma estratégia superior em termos de retorno anualizado, observa-se também uma alta volatilidade.
| Resultados obtidos do agente | |
|---|---|
| Retorno Anualizado | 93,30% |
| Volatilidade Anualizada | 46,67% |
| Sharpe Ratio | 1,64 |
| Máximo Drawdown | -34.50% |
5.3 Análise de Comportamento
A figura abaixo apresenta o histograma dos resultados do Teste de Permutação. As barras cinzas representam a performance do algoritmo quando treinado em dados aleatórios (sem padrão), enquanto a linha vermelha indica o resultado da estratégia com os dados reais.
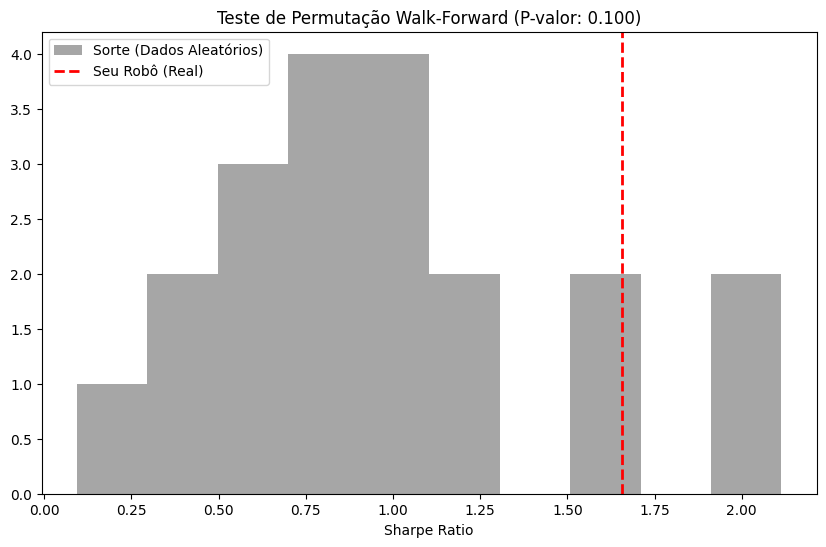
Observa-se que o Sharpe Ratio da estratégia original (1,64) se situa na cauda direita da distribuição. Com um P-valor de 0.1, conclui-se que a estratégia possui significância estatística, indicando que o Aprendizado por Reforço capturou ineficiências reais de mercado e não apenas ruído estatístico.
6. Conclusão
O presente estudo avaliou a viabilidade da aplicação de algoritmos de Aprendizado por Reforço (Reinforcement Learning - RL) na gestão de portfólios, comparando sua performance líquida com estratégias tradicionais consolidadas na literatura financeira: a diversificação ingênua (1/N) e a Otimização de Mínima Variância de Markowitz.
6.1 Resumo dos Achados e Comparação com Benchmarks
Os resultados obtidos demonstram que o agente de RL (PPO) foi capaz de desenvolver uma política de investimentos robusta e lucrativa, mesmo considerando as simulações de fricções de mercado.
Ao responder à questão central do estudo (“o robô superou os benchmarks?”) a resposta é sim, com destaque para a eficiência operacional:
- Rentabilidade real (líquida de custos): um diferencial crítico deste estudo foi a inclusão de custos de transação (turnover cost de 0.1%) diretamente no ambiente de treinamento e teste. Mesmo penalizado por cada rebalanceamento, o agente de RL entregou um Sharpe Ratio de 1.64, superior ao Benchmark 1/N (1.13) e ao portfólio de Markowitz (Sharpe negativo). Isso prova que o algoritmo não apenas “aprendeu a operar”, mas aprendeu a operar de forma eficiente, evitando giros desnecessários que destruiriam valor.
- Perfil de risco: o agente adotou uma postura agressiva, com volatilidade de 46.67% e Máximo Drawdown de -34.50%. Diferente de Markowitz, que priorizou a proteção (MDD de -10.58%), o robô identificou que, no período analisado, a tomada de risco seria recompensada, comportando-se como um fundo de gestão ativa de alta performance.
- Significância estatística: o teste de permutação (Walk-Forward) confirmou, com p-valor de 0.1, que a estratégia possui significância estatística, situando-se na cauda superior da distribuição de resultados possíveis e afastando a hipótese de que os ganhos foram fruto de sorte.
6.2 Limitações do Estudo
Apesar da modelagem rigorosa incluir custos operacionais, algumas limitações persistem:
- Regime de mercado específico: o período de teste (2020-2025) conteve uma recuperação vigorosa pós-pandemia. Embora o robô tenha performado bem neste cenário, não há garantia de generalização para regimes de “Bear Market” secular ou estagflação, onde a agressividade da estratégia poderia resultar em perdas severas.
- Impacto de mercado (Slippage): o estudo incluiu as taxas de transação, mas assumiu que o robô sempre consegue comprar e vender exatamente pelo preço de tela. No mundo real, existe o “Slippage”: muitas vezes o preço muda frações de segundos antes da compra ser confirmada, o que pode diminuir a rentabilidade real da estratégia.
- Interpretabilidade (Black Box): as decisões da rede neural profunda são de difícil auditoria. Entender por que o robô decidiu alocar pesadamente em um ativo específico em detrimento de outro permanece um desafio, dificultando a adoção institucional onde a “tese de investimento” precisa ser explicada a comitês de risco.
6.3 Para Aprimorar a Estratégia
Para aprimorar a estratégia, sugerem-se as seguintes linhas de pesquisa:
- Dados alternativos: enriquecer o conjunto de dados (features) com indicadores macroeconômicos (curva de juros, IPCA) ou análise de sentimento de notícias, permitindo que o agente tome decisões baseadas no ciclo econômico.
- Algoritmos de ator-crítico (A2C/SAC): comparar o PPO com algoritmos como Soft Actor-Critic, que possuem mecanismos de exploração por entropia e podem encontrar políticas mais estáveis e menos voláteis.
Em suma, o projeto evidencia que a Inteligência Artificial é capaz de superar metodologias clássicas mesmo em cenários com custos realistas, oferecendo uma alternativa viável para investidores com maior apetite a risco.
7. Referências
O que é aprendizado por reforço? — Explicação do aprendizado por reforço — AWS
Perspectivas Econômicas Globais
Redalyc.AS TEORIAS DE CARTEIRA DE MARKOWITZ E DE SHARPE: UMA APLICAÇÃO
NO MERCADO BRASILEIRO DE AÇÕES ENTRE JULHO/95 E JUNHO/2000
O que é Proximal Policy Optimization (PPO)? - Glossário de Automação
Índice de Sharpe: o que é e como comparar risco e retorno | XP Investimentos
DeMiguel, V., Garlappi, L., & Uppal, R. (2009). Optimal versus naive diversification: How inefficient is the 1/N portfolio strategy? The Review of Financial Studies, 22(5), 1915–1953. Disponível em: https://academic.oup.com/rfs/article-abstract/22/5/1915/1592901?redirectedFrom=fulltext&login=false
MARKOWITZ, Harry. Portfolio Selection. The Journal of Finance, Vol. 7, No. 1. (Mar., 1952), pp. 77-91
ELTON, Edwin J. et al. Modern Portfolio Theory and Investment Analysis. 9. ed. Wiley, 2014