Autores: Lorenzo Cavalcante, Gabriel Navarro, Rodrigo Catto Menin
_Repositório: link
-
Design Robô A.R.G.O.S.
A.R.G.O.S.

Info
Figura 1: Logo-argos.jpg
-
Nome do Robô
A.R.G.O.S. -
Explicação do Nome: A.R.G.O.S. é um acrônimo para Algoritmo de Reconhecimento Gráfico de Otimização de Sinais. O nome é uma referência direta a Argos Panoptes, o gigante primordial da mitologia grega conhecido como “aquele que tudo vê”[2, 3], um ser com cem olhos que lhe permitia uma vigilância constante.[2, 3] Esta alegoria captura a essência da nossa estratégia. O Reconhecimento Gráfico refere-se à forma como reinventamos a análise técnica, permitindo que nossa abordagem de transfer learning “veja o mercado com seus cem olhos” ao analisar imagens gráficas (GAFs) dos preços, extraindo features aprendidas por backbones visuais pré-treinados e detectando padrões invisíveis à análise estatística convencional. A Otimização de Sinais descreve como essa “visão”, isto é, as representações extraídas via transfer learning, é tratada como um sinal, subsequentemente otimizado e ponderado contra o equilíbrio de mercado pelo modelo Black–Litterman para compor a alocação final.
-
Explicação da Lógica da Estratégia: A lógica do A.R.G.O.S. é uma fusão híbrida de aplicações inovadoras de deep learning e metódos clássicos robustos de teoria de portfólio. Primeiro, o robô “vê”o mercado transformando os dados de preços de 1 trimestre de cada ação em uma imagem de 2 canais (GASF/GADF), então, uma Rede Neural Convolucional (CNN), usando Transfer Learning, analisa essa imagem e a classifica imagem de acordo com a possibilidade do retorno futuros estar entre certos intervalos pré-definidos e fixos. Essa previsão não é um sinal direto de “compra”, mas sim uma “visão”subjetiva. Em seguida, essa “visão”(o retorno esperado Q) e, crucialmente, a “confiança”da CNN nessa visão (Ω) são inseridas no modelo Black-Litterman. O modelo Black-Litterman combina otimamente a visão da nossa IA com o “equilíbrio”do mercado (o retorno neutro Π) e também a matriz de covariância (Σ) resolvendo o clássico problema de instabilidade dos modelos de otimização. O resultado é um portfólio robusto que pondera a previsão da IA pela sua própria confiança, gerando uma alocação de ativos confiável de forma inovadora, tal inovação evita efeitos de crowding no mercado
-
Classe de Ativos Ativos de Renda Variável (Ações)
-
Universo de Investimento S&P100
-
Frequência da Estratégia Trimestral (Rebalanceamento e previsão a cada 63 dias úteis)
-
Benchmark Índice S&P100 (SP100)
2. Página Factsheet
1. Identidade do Robô
• Nome: A.R.G.O.S.
• Slogan: "Vendo padrões além do alcance."
2 e 3. Tese de Investimento (O Porquê) e Universo de Ativos (Onde)
*Padrões de mercado complexos são invisíveis à análise estatística tradicional. Ao converter preços em imagens, podemos usar Redes Neurais Convolucionais (CNNs) para "ver"e explorar dinâmicas dos retornos do S&P100, nosso universo de ativos.*
4. Fluxograma da Lógica (O Como)
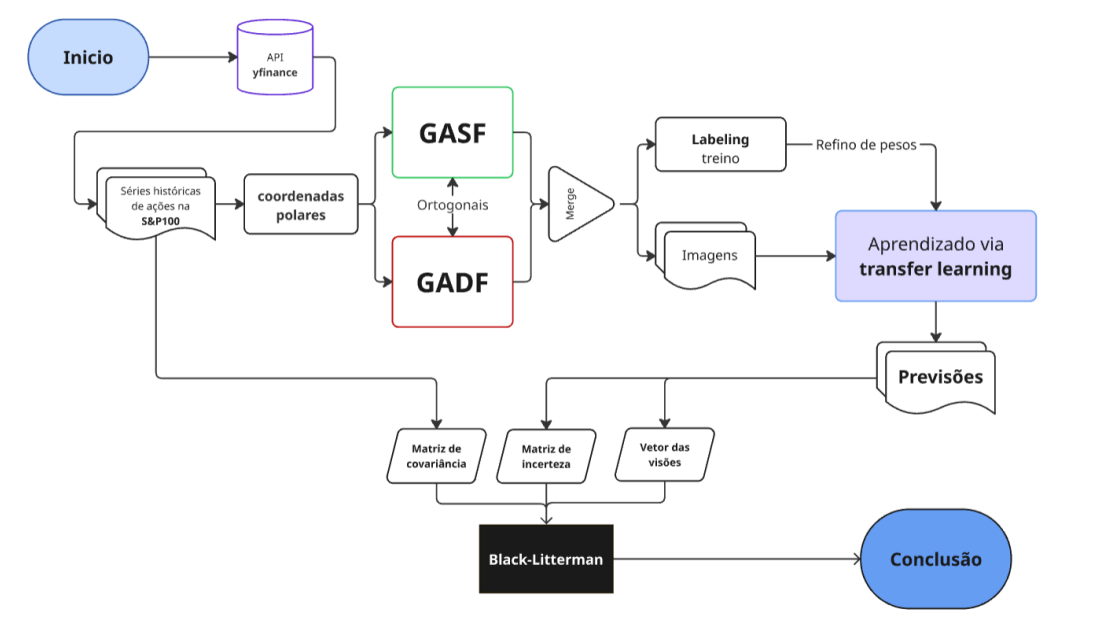
Info
Figura 2: Fluxograma da lógica
3. Desenvolvimento do Trabalho
A) Ideia de Investimento
Nossa ideia foi, em suma, combinar visão computacional com teoria de portfólios. Para tal, fizemos com que uma CNN pre-treináda via transfer learning extraisse padrões das imagens GAF e produzisse visões de mercado (Q); Além disso, fizemos com que o Black–Litterman transformasse essas visões em alocações robustas e bem calibradas ao risco. Intuitivamente, a CNN gera o alpha ao “ver”padrões nas imagens GAF para gerar “visões”de mercado (Q). Enquanto o Black-Litterman constrói o portfólio, usando a teoria de portfólio para alocação robusta e gerenciamento de risco.
O modelo BL recebe a “visão”da CNN (Q) e sua incerteza (Ω). Se a CNN está confiante (Ω baixo), sua visão tem alto peso. Se está “confusa”(Ω alto), a alocação gravita de volta para a âncora estável do equilíbrio, calculada com os 252 dias anteriores à realocação.
Essa arquitetura nos permite alavancar o poder de reconhecimento de padrões de uma CNN pré-treinada em um amplo conjunto de imagens para gerar alpha, enquanto o framework Black–Litterman oferece a âncora de estabilidade que mitiga a instabilidade do ML puro.
Essa arquitetura resolve os dois problemas: a CNN fornece o alpha e o BL fornece a “âncora”de equilíbrio que impede a instabilidade do ML puro.
B) Regra de Investimento
A estratégia é sistematizada em um pipeline de cinco módulos, executado trimestralmente (horizonte de 63 dias).
-
Codificação em Imagem Para cada ativo do S&P100, em cada data de rebalanceamento o script analisa a janela anterior de 63 dias (w = 63). O processo de transformação converte esta série temporal em uma imagem de 2 canais (GAF) da seguinte forma:
- Normalização e Coordenadas Polares: A série temporal é primeiro normalizada (para valores entre -1 e 1). Em seguida, ela é representada em um sistema de coordenadas polares. O valor de cada ponto na série é codificado como o cosseno de um ângulo , e o carimbo de tempo ti é codificado como o raio. Esta representação preserva as relações temporais absolutas.
- Cálculo das Matrizes Gramian: Dai, o algoritmo explora a correlação temporal entre cada ponto i e cada ponto j da série, gerando duas matrizes (imagens): • Canal 1: GASF (Gramian Angular Summation Field): Esta é uma matriz onde cada elemento representa a correlação temporal através da soma trigonométrica. Ela é calculada como o cosseno da soma dos ângulos: GASFi,j = . A matriz resultante captura a superposição de direções ao longo do tempo. • Canal 2: GADF (Gramian Angular Difference Field): De forma complementar, esta matriz captura correlações usando a diferença trigonométrica dos ângulos: GADFi,j = . Estes dois canais (GASF e GADF) são então empilhados para formar uma única imagem de 2 canais. Esta imagem unificada captura diferentes aspectos das correlações temporais e dinâmicas da série de preços, pronta para ser processada pela CNN. Tivemos o cuidado também de checar a ortogonalidade dos dois métodos.
-
Previsão via CNN As imagens GAF (GASF/GADF) geradas são padronizadas e alimentadas em uma Rede Neural Convolucional. Em vez de treinar uma rede massiva do zero, aplicamos Transfer Learning: utilizamos uma arquitetura de CNN robusta (como ResNet) pré-treinada em milhões de imagens (ex: ImageNet)
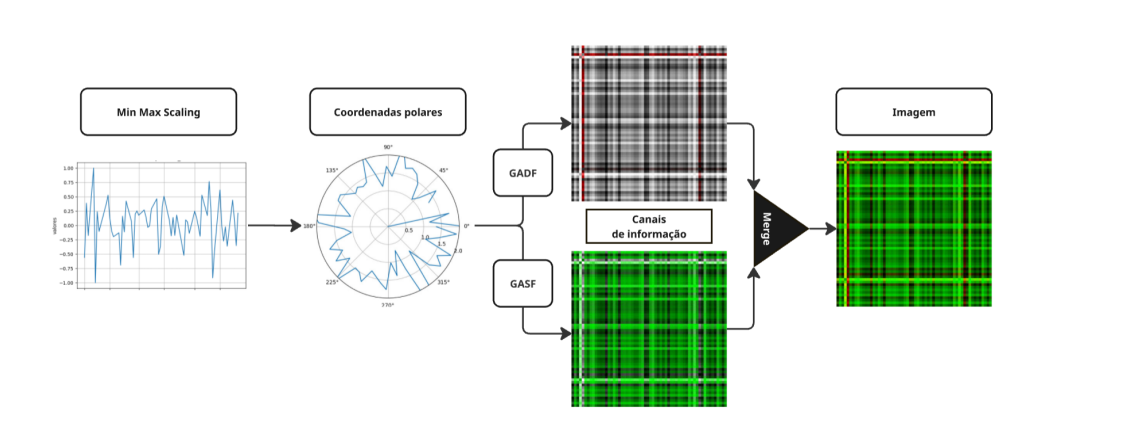
Info
Figura 3: Arquitetura CNN
Figura 3: Exemplo de uma codificação em imagem. e realizamos um fine-tuning nela para a tarefa específica de classificar nossas imagens GAF. Esta abordagem é mais rápida e captura features visuais complexas de forma mais eficaz. • Tarefa: A CNN não prevê um preço. Ela realiza uma classificação multiclasse. • Saída: Um vetor de probabilidade de 5 dimensões, correspondendo aos 5 bins fixos de retorno futuro (63 dias): [←5%], [-5%, -1%], [-1%, 1%], [1%, 5%], [>=5%]. • Métrica de Treino: A rede é ajustada (fine-tuned) usando Categorical Cross-Entropy, otimizando para a precisão da distribuição de probabilidade.
-
A Ponte entre CNN e BlackLitterman Este é o componente central da nossa lógica. Ele consome o vetor da CNN e o traduz para a linguagem do Black-Litterman, gerando as “visões”() e sua “incerteza”().
• Vetor de Visões (): O retorno esperado da visão () para um ativo é a média dos retornos dos bins, ponderada pela probabilidade prevista pela CNN: Onde é o retorno médio esperado para aquele bin, calibrado dinamicamente usando os retornos realizados do trimestre anterior (ver seção ’f’ sobre robustez). • Matriz de Incerteza da Visão (): A confiança da CNN é o inverso da incerteza. Calculamos a incerteza (ωi,i) como a variância da distribuição de retorno prevista pela CNN:
Esta etapa é crucial: uma previsão “confiante” resulta em um baixo, dando alto peso à visão. Uma previsão “incerta”resulta em um ω alto, fazendo com que o modelo ignore a visão da CNN e prefira o equilíbrio de mercado. A matriz é uma matriz diagonal contendo esses valores.
• Matriz de Covariância de Mercado (): O modelo também calcula a matriz de covariância de risco ( ) usando uma janela móvel de 252 dias (1 ano), com shrinkage de Ledoit-Wolf para robustez.
-
Otimização de Portfólio Este módulo executa a alocação final em duas etapas a cada trimestre ( ), utilizando os sinais Qτ , Ωτ , e Στ gerados. • Etapa 1: Cálculo do Retorno Black-Litterman () O script primeiro calcula os retornos de equilíbrio de mercado (neutros) (via reverso: ). Em seguida, ele resolve a equação mestre do Black-Litterman , que combina o equilíbrio com as visões da nossa CNN (ponderadas pela incerteza e ): • Etapa 2: Otimização de Média-Variância O vetor de retorno combinado µˆBL,τ (que é muito mais estável do que o Q bruto da CNN) é então usado como o vetor de retorno esperado em um otimizador de Média-Variância padrão, que resolve o vetor de pesos final w: Onde é a aversão ao risco do investidor e κ é uma penalidade de turnover para controlar custos de transação, definidas, respectivamente, como 0,03 e 10bps A partir desse output calculamos os resultados e as métricas finais do backtest.
C) Origem da Ideia
No início da análise técnica, traders tomavam decisões de investimento baseadas puramente na inspeção visual de gráficos de preços, buscando padrões. Apesar de relevante na sua época, esta abordagem era subjetiva e limitada. Com nossa abordagem inovadora, o robô A.R.G.O.S., buscamos reinventar esse método clássico de trading, não mais como uma análise superficial feita por humano, mas como uma análise feita por Inteligência Artificial de uma imagem complexa de dois canais(GASF/GADF), extraindo padrões significativos que o olho e a mente humana são incapazes de captar. A partir dai, temos um sinal que será incorporado no clássico modelo Black-Literman para gerar retorno.
Utilizamos alguns artigos para fundamentar nossa abordagem, o principal foi a proposta criada por Wang e Oates [1] de utilizar o GAF como transformação da série temporal em imagem e depois aplicar uma CNN para prever a imagem futura, e o artigo seminal do Black-Litterman, fundamental para gerarmos alpha com nosso sinal.
A pesquisa de Wang e Oates foi a mais importante para nós, pois demonstrou que a codificação de séries temporais em Gramian Angular Fields (GAF) cria representações de imagem que (a) preservam a dependência temporal e (b) podem ser consumidas eficazmente por Redes Neurais Convolucionais para classificação. Isso nos permitiu reformular o problema de previsão de séries temporais como um problema de visão computacional com fundamentos bem robustos.
D) Universo de Dados
• Universo Investível: Ações do S&P 100. • Fonte dos Dados: Yahoo Finance, dados diários. • Período de Análise: Dados de 2010-2025, com preços diários das ações do S&P100 no período, separados com proporções 70/30. • Tratamento e Limpeza: (image_pre_processing.py)
Utilizamos os auto-adjust do yfinance para os preços de fechamento e abertura. Entretanto, empresas que sofreram fusões tem seus dados afetados, deixando o cálculo inviável apenas usando o yfinance, elas foram consideradas como NaN e descartadas do universo, essas constituindo menos de 5% das ações. • Transformação em imagem: (image_transformation.py) A combinação de min_max_scaler e cos−1 sempre gerará ao menos duas linhas bem claras que se destacam das demais. Não há evidências fortes que isso impacte a robustez dos resultados.
• Transformação em imagem: (image_transformation.py)
A combinação de min_max_scaler e cos−1 sempre gerará ao menos duas linhas bem claras que se destacam das demais. Não há evidências fortes que isso impacte a robustez dos resultados
E) Resultados
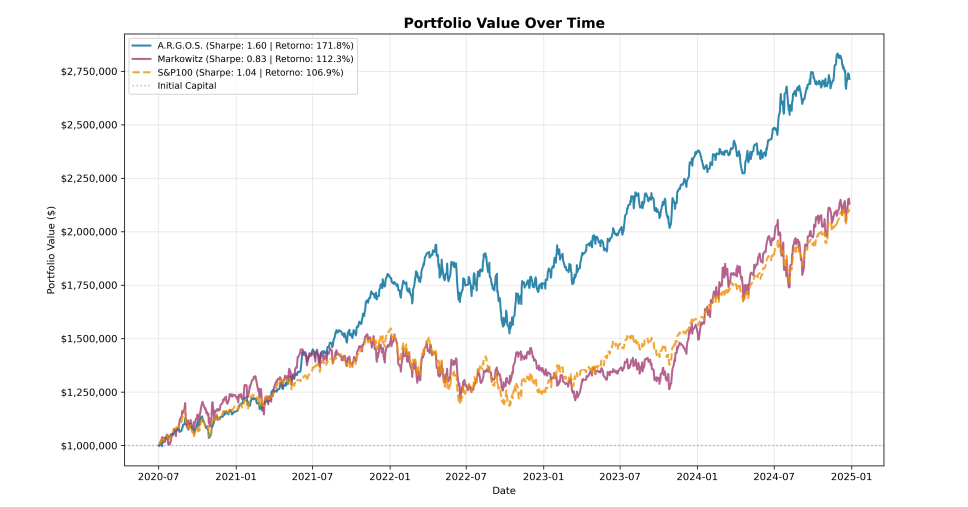
Info
Figura 4: Série Histórico do valor do Portfólio
| Métrica | A.R.G.O.S. | Markowitz | S&P100 |
|---|---|---|---|
| Desempenho | |||
| Capital Inicial ($$$) | 1.000.000 | 1.000.000 | 1.000.000 |
| Valor Final ($$$) | 2.713.845 | 2.129.948 | 2.076.993 |
| Retorno Total () | 171.38 | 112.99 | 107.70 |
| CAGR () | 25.39 | 18.69 | 18.01 |
| Métricas Ajustadas ao Risco | |||
| Volatilidade Anual () | 15.87 | 22.48 | 17.33 |
| Razão de Sharpe | 1.60 | 0.83 | 1.04 |
| Razão de Sortino | 2.46 | 1.19 | 1.44 |
| Máximo Drawdown () | |||
| Estatísticas Operacionais | |||
| Rebalanceamentos | 17 | 17 | 0 |
| Turnover Médio () | 170.58 | 87.68 | 0.00 |
| Custos de Transação ($$$) | 27.099 | 10.686 | 0 |
| Taxa de Vitória () | 55.94 | 55.22 | 54.41 |
| Período (anos) | 4.4 | 4.4 | 4.4 |
| Os resultados demonstram que a estratégia A.R.G.O.S. supera consistentemente o benchmark S&P100 e o Portfólio de Markowitz clássico em métricas de retornos e ajustadas ao risco. Mesmo com um custo de transação maior devido aos turnovers. Faremos uma breve análise comparativa de risco (A.R.G.O.S vs. Markowitz) usando o teste . Esse teste verifica, de forma direta: |
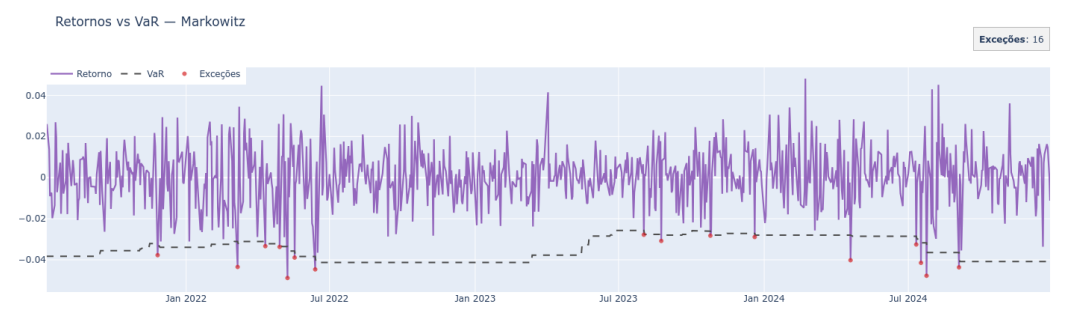
Comecemos por duas visualizações que mostram como o A.R.G.O.S viola menos o Value at Risk do que o modelo clássico de Markowitz.
Em seguida, aplicamos o DQ-test — um cheque rápido (e formal) de dois pontos: • Calibração condicional do VaR: dado o que já sabíamos no tempo t (incl. V aRt), a chance de violação é = 1%?
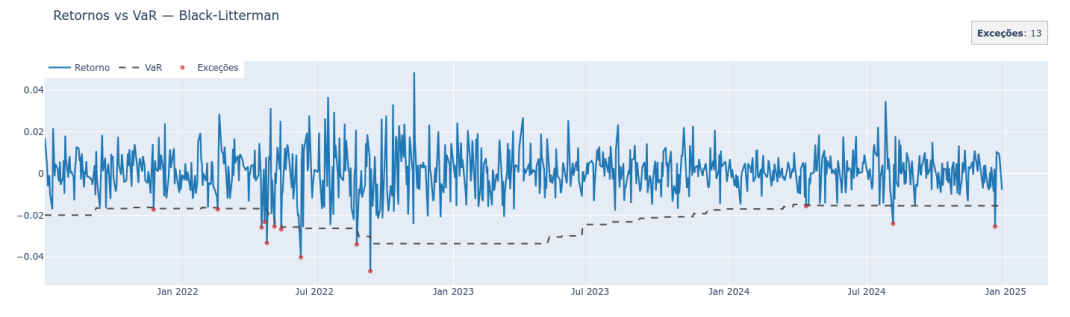
Info
Figura 5: Violações do VAR no modelo A.R.G.O.S (Black-Litterman)
Info
Figura 6: Violações do VAR no modelo Markowitz
• Independência das violações: os hits não vêm em “rajadas” (sem clustering), o que verificamos com defasagens de It.
Tabela 2: Sumário do teste DQ por estratégia
| Estratégia | Wald | (Wald) | (LM) | |
|---|---|---|---|---|
| A.R.G.O.S | 0.010 | 8.003 | 0.238 | 0.198 |
| Markowitz | 0.010 | 26.937 | 0.000 | 0.152 |
- -valor: probabilidade de observar uma estatística tão extrema sob .
- Wald: teste global de (todos os coeficientes do DQ); não rejeitar sugere boa calibração e ausência de dependência remanescente.
- LM: teste global alternativo baseado em regressão auxiliar; usado como checagem de robustez.
No nível 1%, não rejeita no Wald ( 0,2379) e Markowitz rejeita ( 0,000149); o LM para Markowitz não rejeita (p = 0,1524), não adicionando evidência global extra. Pelos coeficientes, a calibração do quantil é estável em BL ( não significativo: 0,66 < 2 × 0,46) e falha em Markowitz (2,16 > 2 × 0,76). Quanto à memória, BL mostra evidência fraca (apenas lag 1 marginal); em Markowitz, lags 1–3 são significativos, caracterizando clustering de exceções, e a constante significativa sugere viés de cobertura. Ou seja BL aparenta ser melhor calibrado e com menor memória enquanto Markowitz apresenta pior calibração condicional e memória mais pronunciada.
F) Processo de Backtest
A robustez de um backtest é definida pelos seus cuidados metodológicos contra vieses4 . Seguimos um protocolo rigoroso para garantir que nossos resultados sejam o mais realistas possível, conforme detalhado no pipeline do readme.
Tabela 3: Coeficientes essenciais do teste DQ (α = 1%, lags= 4)
| Estratégia | Regressor | β | SE (HAC) |
|---|---|---|---|
| A.R.G.O.S. | Constante | 0.018 | 0.012 |
| A.R.G.O.S. | Exceção defasada (1) | 0.008 | |
| A.R.G.O.S. | Exceção defasada (2) | 0.064 | 0.071 |
| A.R.G.O.S. | Exceção defasada (3) | 0.064 | 0.069 |
| A.R.G.O.S. | Exceção defasada (4) | 0.009 | |
| A.R.G.O.S. | Nível do VaR () | 0.657 | 0.456 |
| Markowitz | Constante | 0.084 | 0.030 |
| Markowitz | Exceção defasada (1) | 0.006 | |
| Markowitz | Exceção defasada (2) | 0.006 | |
| Markowitz | Exceção defasada (3) | 0.006 | |
| Markowitz | Exceção defasada (4) | 0.040 | 0.059 |
| Markowitz | Nível do VaR () | 2.155 | 0.760 |
- : efeito do regressor sobre (ideal ).
- SE (HAC): erro-padrão consistente a heterocedasticidade e autocorrelação.
- Regressores: Exceção defasada (k) testa independência dos hits (memória/clustering); testa a calibração condicional do nível do quantil.
-
Prevenção de Look-Ahead Bias (Vazamento de Dados) Este é o viés mais crítico em finanças quantitativas. A.R.G.O.S. foi projetado para ser 100% livre de look-ahead bias através de uma calibração dinâmica. Isso vale para a matriz de covariância que foi calculada em janela deslizante com os dados dos 252 dias anteriores, garantimos a consistência temporal no processo de criação de imagens e de alimentação da CNN.
-
Prevenção de Overfitting O overfitting é o principal risco dos modelos de ML, ainda mais incorporado no Black-Litterman. Nós o mitigamos em duas camadas: • Camada CNN: O próprio uso de Transfer Learning é um poderoso regularizador. Ao invés de aprender milhões de parâmetros do zero, nós apenas ajustamos (fine-tune) as camadas finais de uma rede pré-treinada. Isso reduz drasticamente o número de parâmetros livres e ancora o modelo em features visuais robustas.
-
Simulação de Custos de Fricção Nosso backtest inclui custos implícitos e explícitos, respectivamente, uma penalidade de e função de custo para contabilizar possíveis taxas que existem no mercado.
-
Survivorship Bias Evitamos Survivorship Bias fazendo webscraping de todos os tickers presentes no S&P100, mesmo os já delistados ou que passaram por fusões/divisões. Garantindo que não houve viés de escolha ou sobrevivência.
G) Conclusão.
A.R.G.O.S demonstra ser uma estratégia de investimento robusta e inovadora, validando nossa tese central. Os resultados indicam que a fusão do deep learning com teoria de portfólio gera alfa consistente.
A estratégia provou não ser apenas um exercício acadêmico; ela foi projetada com rigor metodológico, evitando quase todos os vieses, mas também uma promissora estratégia a ser aplicada no mercado em simulações reais.
Próximos Passos: Queremos aplicar em dados out-of-sample (walk-forward) em tempo real. Os próximos passos para evolução incluem: - Divisão dos intervalos do vetor de probabilidade como a resolução de um problema de otimização; - Teste da estratégias em dados melhores; - Implementação de um modelo analogo com informações intra-diárias para previsões mensais; - Testar outras arquiteturas de imagem além do GAF de 2 canais.
4. Página IA Generativa.
1. Ferramentas Utilizadas
• ChatGPT
• Gemini
• Copilot
• Claude Sonnet
2. Etapas do Projeto onde Aplicamos IA e Exemplos
Brainstorming: Consolidação de ideias seminais e estruturação de esqueletos de projetos para avaliação de viabilidade.
Raspagem de dados: Geração (via Gemini 2.5 Plus) de um CSV com o histórico de tickers do S&P 100 (2010-2025) e auxílio na coleta de artigos acadêmicos.
Programação: Otimização e concisão do pipeline (Claude Sonnet 4.5) e aceleração da codificação de rotinas (Copilot), sem substituir a lógica de desenvolvimento.
Debugging: Identificação de erros críticos, incluindo inconsistências nas labels das imagens da CNN e um erro de lookahead bias no cálculo da matriz de covariância (detectado pelo Gemini).
Redação do Relatório: Revisão gramatical e de coesão, correção de sintaxe LaTeX e criação de um checklist dinâmico para garantir o cumprimento dos requisitos.
Design: Criação da identidade visual do robô (A.R.G.O.S.) e desenvolvimento do acrônimo e (usando ChatGPT).
3. Limitações ou Erros
• Como cada membro estava usando uma IA diferente, acabamos tendo problemas de compatibilidade dos arquivos .py dentro do pipeline, o que teve que ser resolvido manualmente; • O texto gerado por IA é bastante genérico e repetitivo, falhando em transmitir as informações de forma concisa e coesa; • Ao encontrar problemas de ausência de dados, a IA criava dados falsos para suprir sua necessidade, o mesmo ocorreu na pesquisa de artigos, quando nos deparamos com artigos que não existiam.
4. Reflexão Final
A IA generativa não pode e não deve ser utilizada como resolução “caixa-preta”para todos os problemas, todas as vezes que tentamos usá-la desse modo acabamos caindo no erro. No fim, ela não passa de um ajudante bastante prestativo e perspicaz, mas é essencial que a parte crítica e criativa humana esteja em dia para que o uso da IA seja proveitoso.