Autores: Gustavo Katsuo Tsuitsui, Gabriel Graciano Dias
Repositório: GitHub - fea-dev-usp/case-IA-grupo-02: Repositório do grupo 2 para o case de IA da capacitação 2025/2. · GitHub
1. Introdução e Contexto
O Brasil possui 5.570 municípios com realidades desiguais. A gestão tradicional de saúde pública, baseada em médias estaduais, falha ao ignorar que cidades ricas podem ter gestão ineficiente e cidades pobres podem ser referências em atenção básica.
1.1 Problema
Identificar padrões de eficiência e vulnerabilidade que não são visíveis em análises geográficas simples e detectar cidades anômalas que fogem de algum padrão estatístico esperado.
1.2 Objetivo
Desenvolver uma aplicação de Inteligência Artificial capaz de:
1. Clusterizar os municípios em grupos de semelhança (não por região, mas por indicadores).
2. Detectar Anomalias usando Deep Learning para apontar possíveis fraudes ou erros de dados.
3. Visualizar os resultados em um Dashboard interativo.
2. Metodologia (Pipeline de Dados)
2.1 Engenharia de Dados
Os dados foram coletados de fontes governamentais oficiais (DATASUS e IBGE) abrangendo indicadores de Economia, Demografia, Mortalidade e Eficiência Hospitalar.
● Fontes: Sistema de Informações sobre Mortalidade (SIM), Nascidos Vivos (SINASC) e Internações Hospitalares (SIH).
● Tratamento: Limpeza de valores nulos, normalização de nomes de municípios e criação de indicadores calculados (ex: Taxa de Internações por Condições Sensíveis à Atenção Primária - ICSAP).
2.2 Modelagem: Machine Learning (Clustering)
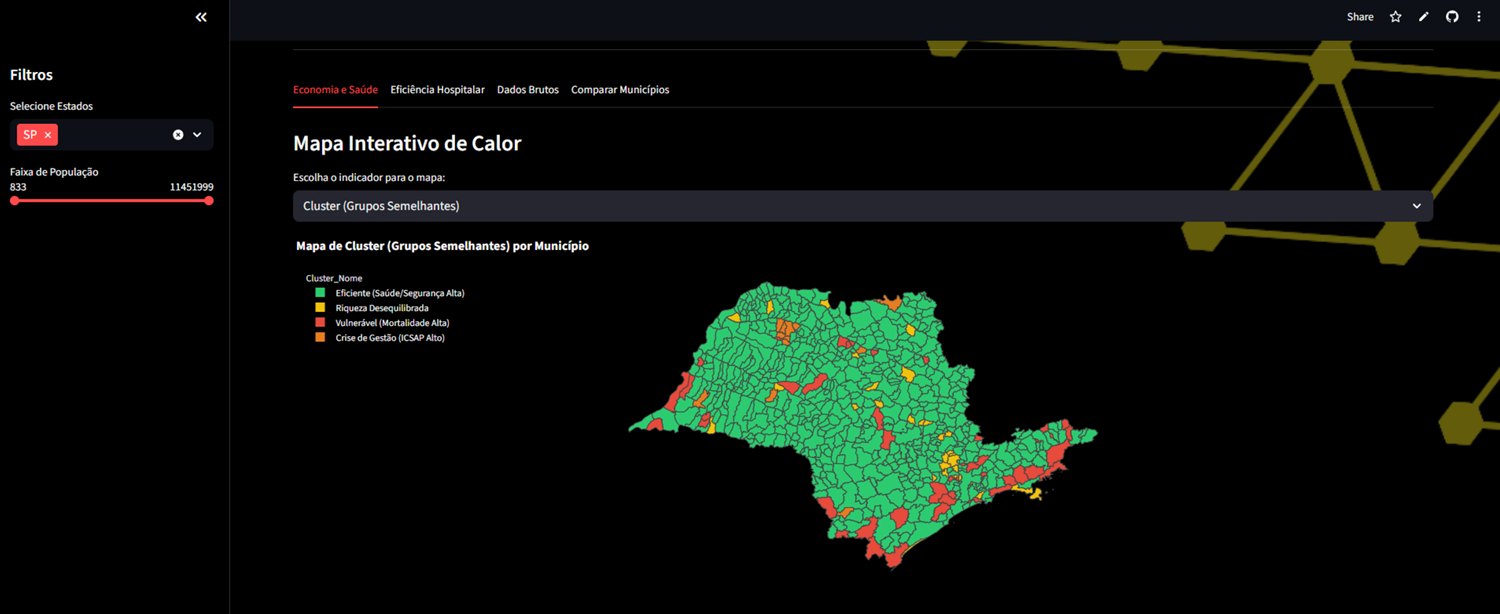
Utilizamos o algoritmo K-Means para segmentar o Brasil. O número ideal de clusters (k=4) foi definido pelo método do Cotovelo (Elbow Method).
Definição dos Perfis Encontrados:
● Cluster 0 - Eficiente: Indicadores equilibrados e boa eficiência de gastos.
● Cluster 1 - Crise de Gestão: Cidades com alta taxa de internações evitáveis (ICSAP), indicando falha na atenção básica.
● Cluster 2 - Riqueza Desequilibrada: PIB alto, mas com índices de violência ou mortalidade acima do esperado para a renda.
● Cluster 3 - Vulnerável : Baixo PIB, alta dependência do SUS e indicadores de saúde críticos.
2.3 Modelagem: Deep Learning (Anomalias)
Implementamos um Autoencoder (Rede Neural Artificial) usando TensorFlow.
● Lógica: A rede aprendeu a “comprimir” e “reconstruir” os dados dos municípios “normais”.
● Detecção: Municípios que a rede não conseguiu reconstruir bem (alto Erro de Reconstrução) foram marcados como anomalias matemáticas. Isso aponta para cidades com comportamento atípico.
3. Resultados e Análises
3.1 Panorama Nacional (Mapa de Clusters)

3.2. Casos extremos
Surgem casos de borda, principalmente em municípios pequenos. Por exemplo, municípios com taxa de mortalidade infantil igual a 0 ou municípios pouco populosos levam a um aumento desproporcional de algumas métricas. Isso impacta diretamente no cluster em que são alocados. Uma possível solução a esse problema a agregação por um período maior de tempo. Um exemplo é o município de Mineiros do Tietê - SP, com população de 11230 habitantes e taxa de mortalidade infantil igual a 0 para o período considerado, ou Oscar Bressane - SP com população de 2470 habitantes e taxa de mortalidade infantil de 66.66 óbitos por mil nascidos (considerado extremamente elevado).
4. Produto Final: Dashboard
Para garantir a aplicabilidade do projeto, desenvolvemos um Data App utilizando a biblioteca Streamlit. A ferramenta permite filtrar dados por estado, comparar municípios com a média de seus clusters e visualizar o um panorama da saúde municipal. Link: https://grupo2-teste1-dev.streamlit.app/
Melhorias Futuras:
Como melhorias futuras, pode-se elaborar um pipeline de ETL automático dos dados, via schedule no Git Actions, por exemplo. Dessa forma, o dashboard encontraria-se em constante atualização. Pode-se, também, ampliar as bases de dados utilizadas, buscando informações como escolaridade e saneamento básico. Espera-se que essa adição aumente o R². Por fim, pode-se estruturar uma geração automática de relatórios em formato pdf para melhor leitura.
6. Referências e Bibliografia
● Linguagem: Python 3.11
● Machine Learning: Scikit-Learn (K-Means), TensorFlow (Autoencoders).
● Visualização: Plotly, Streamlit, Geopandas.
● Fontes de Dados: DATASUS (OpenDataSUS) e IBGE (Sidra).