Autores: Gabriela Saito · Lucas Marino · Maria Eduarda Alonso Repositório: grupo-3-projeto
1. Introdução do Projeto
O planejamento previdenciário é um dos maiores desafios do investidor de longo prazo, especialmente em um cenário de incertezas econômicas, mudanças demográficas e questionamentos sobre a sustentabilidade dos sistemas tradicionais de aposentadoria. Nesse contexto, a construção de uma carteira de investimentos capaz de gerar renda recorrente, com baixo risco e alto grau de diversificação, torna-se essencial para garantir segurança financeira no futuro.
Este projeto tem como objetivo desenvolver uma carteira previdenciária automatizada, utilizando dados financeiros, matemática e métodos quantitativos para construir uma carteira de aposentadoria capaz de gerar a maior renda possível de forma segura, diversificada e focada em dividendos. A proposta combina fundamentos clássicos de finanças com técnicas modernas de análise de dados e aprendizado de máquina, eliminando decisões subjetivas e reduzindo vieses humanos no processo de alocação de capital.
A construção idealizava um funil de decisão em três etapas complementares. Primeiramente, é feito um filtro básico para garantir que empresas sólidas e financeiramente saudáveis componham a base da carteira. Em seguida, técnicas de aprendizado de máquina são utilizadas para identificar padrões de comportamento entre os ativos e promover uma diversificação eficiente. Por fim, métodos de finanças quantitativas são empregados para determinar a alocação ótima de recursos, equilibrando risco e retorno com foco na geração consistente de dividendos.
O resultado final é uma carteira previdenciária quantitativa, orientada à geração de renda constante e projetada para o longo prazo, que pode ser reproduzida, testada e adaptada conforme diferentes perfis de risco e cenários de mercado.
2. Coleta de Dados
Um dos principais desafios para a construção do código foi a elaboração do conjunto de funções responsável pela coleta, organização e padronização de dados para compor a base de dados a ser processada. O objetivo principal é fornecer uma base de dados confiável e consistente para as etapas posteriores de filtragem, análise quantitativa e seleção de ativos da carteira previdenciária.
O Fundamentus é uma ferramenta online voltada para investidores que desejam realizar análise fundamentalista de empresas listadas na B3. A base de dados da plataforma consolida múltiplos financeiros essenciais, como o P/L (Preço/Lucro), DY (Dividend Yield) e ROIC, extraídos diretamente dos balanços e demonstrativos de resultados oficiais das companhias. No contexto do código, a base fundamentus funciona como uma ponte que captura esses indicadores em tempo real, filtrando o mercado inteiro em segundos, em vez de consultar papel por papel.
A principal dificuldade ao usar o Fundamentus com bibliotecas modernas como o yfinance é o conflito de dependências. O fundamentus exige versões antigas das bibliotecas requests e requests-cache para funcionar, enquanto o yfinance e o pandas atualizados requerem versões recentes. Caso se tente instalar ambos normalmente, o instalador do Python (pip) entrará em um ciclo de desinstalar uma versão para colocar a outra, impedindo que o código rode.
Diante desse problema, encontramos duas soluções. Para que o código rode em qualquer computador, a primeira consiste no uso da instalação com o parâmetro --no-deps. Este processo consiste na instalação primeiro das bibliotecas mais pesadas e modernas (yfinance, pandas) e, por último, instalar o fundamentus sem permitir que ele traga suas dependências antigas junto. Além disso, como a biblioteca tenta criar um banco de dados local para cachê, é necessário garantir que o script esteja rodando em uma pasta com permissões de escrita, como o diretório de usuário (Home), para evitar o erro sqlite3.operationalError.
No entanto, apesar do problema dos conflitos ser resolvido através dos parâmetros acima, pode-se descobrir com sua execução outro empecilho. Tecnicamente, a biblioteca fundamentus opera através de webscraping. Ao executar o comando get_resultado(), o código faz uma requisição HTTP para o site, lê a tabela HTML de ativos e a converte em um DataFrame do Pandas. A biblioteca, não tendo relação oficial com o site Fundamentus, realiza o webscraping de uma versão antiga do site, de modo que diversas informações essenciais para a análise são perdidas.
A segunda solução, sendo esta a empregada no código, envolve um fluxo dividido em três etapas principais:
- Coleta dos dados brutos por setor
- Mapeamento dos setores disponíveis
- Filtragem, padronização e enriquecimento dos dados
A função tabela_completa_dos_dados é responsável por acessar o site Fundamentus e extrair
tabela de indicadores financeiros correspondente a um setor específico.

O identificador do setor (id_setor) é utilizado para a construção dinâmica da URL de consulta. A requisição HTTP é realizada com um User-Agent customizado, reduzindo a probabilidade de bloqueio pelo servidor. A função pandas.read_html converte as tabelas HTML retornadas em um DataFrame, respeitando o padrão brasileiro de separadores decimais e de milhar. Em caso de erro de conexão ou ausência de tabelas válidas, a função retorna um DataFrame vazio, garantindo a robustez do processo.
A função dicionario_de_setores tem como finalidade identificar todos os setores econômicos disponíveis no site, criando um dicionário que relaciona o ID do setor ao seu nome descritivo.

A página de busca avançada do Fundamentus é analisada por meio de web scraping com o auxílio da biblioteca BeautifulSoup. O campo HTML <select> que contém os setores é localizado, e cada opção válida é processada. O retorno final da função é um dicionário no formato {id_setor: nome_do_setor}, essencial para permitir a iteração automática sobre todos os setores e para enriquecer os dados com informações textuais compreensíveis.
A função tabela_filtrada_por_setor é responsável por transformar a tabela bruta coletada em um DataFrame estruturado, contendo apenas as variáveis relevantes para a análise fundamentalista. Inicialmente, o conjunto de dados recebe informações de identificação do setor. Em seguida, ocorre a padronização dos nomes das colunas, garantindo consistência semântica entre diferentes setores. A função define explicitamente um subconjunto de indicadores financeiros considerados relevantes para o projeto, tais como dividend yield, múltiplos de valuation, rentabilidade e indicadores de endividamento.
Após a seleção das colunas disponíveis, os dados passam por uma função auxiliar de tratamento (tratar_dataframe_fundamentus), responsável pela limpeza, conversão de tipos e padronização numérica.
Por fim, é calculado um indicador adicional de interesse do projeto: o Payout estimado, definido como o produto entre Dividend Yield e P/L, servindo como aproximação do percentual de lucro distribuído. Caso os dados necessários não estejam disponíveis, o valor é definido como zero, evitando falhas no processamento.
Esse módulo estabelece a base de dados fundamentalista do projeto, garantindo que as informações sejam coletadas de forma automatizada, padronizada e resiliente a falhas externas. O resultado é um conjunto de tabelas prontas para alimentar os filtros de qualidade, os algoritmos de aprendizado de máquina e os modelos de otimização da carteira previdenciária.
3. Filtros de Qualidade
3.1 Filtro Setorial
Nesta etapa do código, após a realização do processo de web scraping (raspagem de dados) no site Fundamentus das ações das empresas listadas na B3 (Bolsa de Valores Oficial do Brasil), bem como dos setores em que essas empresas atuam e de métricas fundamentalistas respectivas a essas empresas.
Com a relação entre as ações das empresas e seus respectivos setores já obtida, é aplicado um filtro que seleciona apenas as empresas atuantes em setores perenes, isto é, setores de base, como energia, saneamento, entre outros. Dessa forma, obtém-se uma base composta por ações de empresas sólidas.
3.2 Filtro Através de Métricas Financeiras
Após definida a base composta por empresas sólidas, é aplicado um novo filtro que seleciona aquelas empresas que têm ações que atendem às seguintes métricas fundamentalistas: Liquidez Corrente, EV/EBITDA, Cotação, P/L, ROE e Volatilidade Média.
Cada uma dessas métricas fornece informações sobre a situação financeira e o perfil da ação. A ’Liquidez Corrente’ indica a capacidade de solvência da empresa no curto prazo; o ’EV/EBITDA’ estima quantos anos de geração operacional seriam necessários para “pagar” o valor da firma, assumindo estabilidade; a ’Cotação’ reflete a avaliação marginal do mercado sobre a empresa, incorporando expectativas, liquidez, risco e informações disponíveis; o ’P/L’ representa o custo do lucro para o investidor ou, de forma inversa, o retorno implícito do capital investido; o ’ROE’ mede a eficiência da empresa em converter patrimônio líquido em resultado; e a ’Volatilidade Média’ expressa o nível de incerteza percebido pelo mercado em relação aos fluxos futuros da empresa.
Os dados referentes a essas métricas que foram obtidos através do web-scraping feito anteriormente, terão os seguintes valores e implicações econômicas como parâmetro para o filtro:
-
Liquidez Corrente > 0: a empresa mostra que não se encontra insolvente no curto prazo; caso o parâmetro esteja abaixo desse limite, não haveria uma interpretação econômica válida, e a métrica deixaria de representar adequadamente a solvência.
-
EV/EBITDA > 0: essa métrica indica que a empresa possui geração operacional positiva. Caso o parâmetro seja menor que zero, isso significa que o EBITDA < 0, o que implica uma operação deficitária, ou que o EV < 0, indicando uma estrutura de capital distorcida. Em qualquer um dos casos, só há interpretação de valuation quando EV/EBITDA > 0.
-
Cotação > 3: essa métrica indica que a ação possui um nível mínimo de liquidez de mercado e não se enquadra como “penny stock”. Caso o parâmetro esteja abaixo desse limite, o preço passaria a refletir mais aspectos da microestrutura de mercado do que os fundamentos da empresa.
-
-50 < P/L < 50: a empresa encontra-se dentro de uma faixa economicamente analisável. O parâmetro adota esse intervalo de valores, pois, se a métrica for inferior a -50, o lucro perde completamente seu significado; por outro lado, se for superior a 50, a métrica passa a refletir expectativas futuras, e não o lucro atual.
-
-50% < ROE < 100%: o retorno sobre o capital próprio encontra-se dentro de um intervalo economicamente plausível. O parâmetro adota essa faixa de valores, pois, abaixo de -50%, o risco de insolvência patrimonial torna-se elevado, enquanto valores acima de 100% geralmente indicam um patrimônio artificialmente reduzido e baixa sustentabilidade ao longo do tempo.
-
Volatilidade Média < 100% ao ano: a ação apresenta um risco de mercado controlável e um comportamento estatístico estável. Caso o parâmetro ultrapasse esse limite, o mercado passa a precificar um nível de incerteza extrema, e a ação tende a se comportar de forma opcional ou predominantemente especulativa.
Dessa forma, apenas as ações das empresas que atenderam aos valores estabelecidos para esses parâmetros foram selecionadas para serem efetivamente analisadas.
A aplicação conjunta do filtro setorial e do filtro por métricas financeiras visou a construção de uma base de ativos alinhada aos objetivos de estabilidade e recorrência de uma carteira previdenciária. Ao restringir a análise a empresas inseridas em setores perenes e, simultaneamente, impor critérios quantitativos economicamente plausíveis, o processo busca eliminar ativos com fundamentos frágeis, distorções de mercado ou perfil excessivamente especulativo.
Dessa forma, os filtros de qualidade cumprem o papel de reduzir o universo inicial de ações a um conjunto mais homogêneo, sólido e interpretável, criando condições adequadas para a aplicação das etapas subsequentes do modelo, como a análise de agrupamento, a diversificação quantitativa e a otimização da alocação de recursos.
4. Análise Clustering
4.1 Clustering através do K-Means
Após a definição dos indicadores financeiros a serem utilizados como critérios para o agrupamento de papéis e para a diversificação da carteira, foi realizada a importação da biblioteca K-Means. O objetivo é agrupar as ações com comportamentos semelhantes em um mesmo cluster, permitindo a separação de perfis que viabilizem a distribuição de ativos na carteira previdenciária em desenvolvimento.
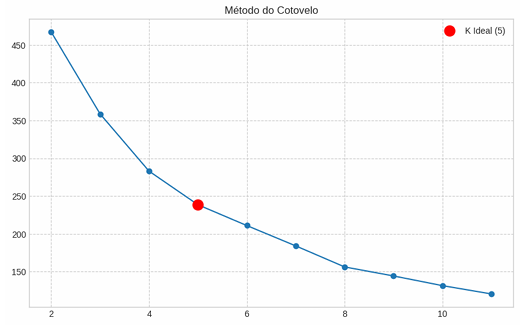
O K-Means é um algoritmo de aprendizado não supervisionado baseado em centróides, isto é, divide um conjunto de dados em agrupamentos, considerando a distância entre um ponto e a média de todos os elementos do mesmo grupo. Para aplicar esse método, é necessário definir o número inicial de clusters (k) a ser utilizado, para que o modelo encontre agrupamentos condizentes com essa quantidade. Assim, para estipular o parâmetro “k”, utilizamos o Método do Cotovelo.
4.2 Método do Cotovelo
O Método do Cotovelo (Elbow Method) é uma forma visual de determinar a quantidade ideal de clusters por meio de um modelo iterativo que testa diferentes valores de “k” de forma crescente até atingir o equilíbrio entre o número de partições e a dispersão dos conjuntos.
Em geral, ao aumentar o total de clusters, a variância interna tende a diminuir, dado que mais agrupamentos tornam cada grupo mais específico e o centro tende a ficar mais próximo dos pontos semelhantes. No entanto, após certa quantidade de conjuntos, a redução da variação interna torna-se menos significativa, indicando retornos marginais decrescentes.
Assim, é preciso ponderar entre o ganho na qualidade do agrupamento e o aumento da complexidade do modelo. Em resumo, o ideal é encontrar o equilíbrio em que os itens de cada partição sejam parecidos entre si e, ao mesmo tempo, diferentes dos elementos dos demais grupos. Visualmente, isso é indicado a partir de um ponto de inflexão no gráfico, onde a inclinação da curva se altera, formando um “cotovelo”.
A aplicação dessa abordagem na base de dados resultou no gráfico abaixo, que apresenta a relação entre o número de clusters “k” e a variação interna dos grupos. Portanto, o ideal é utilizar cinco conjuntos para a divisão dos papéis do dataframe filtrado.
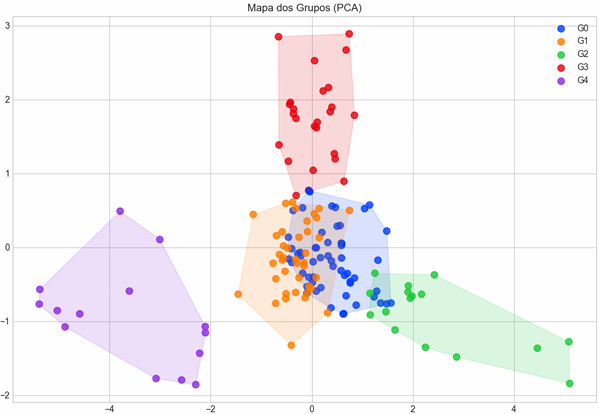
4.3 Agrupamento de papéis
Após aplicação do K-Means, considerando a quantidade ideal de clusters pelo Método do Cotovelo, foram obtidos cinco agrupamentos: G0, G1, G2, G3 e G4. A fim de avaliar e interpretar a disposição das ações clusterizadas graficamente, foi utilizada a técnica PCA (Principal Component Analysis) para reduzir os critérios originais, com muitas variáveis, em apenas duas dimensões que concentram a maior parte da variação dos dados, o que viabiliza a plotagem em dois eixos.
A partir da visualização abaixo, é possível notar que os agrupamentos criados contêm pontos espacialmente próximos, uma vez que a distância no gráfico reflete a similaridade entre os papéis. Ou seja, os pontos vizinhos tendem a compartilhar parâmetros financeiros comparáveis, enquanto os mais distantes indicam perfis comportamentais diferentes. Esse padrão é reforçado pela criação de polígonos, áreas sombreadas, que representam a “área de influência” de cada cluster. Apesar de não serem fronteiras exatas do K-means, possibilitam a visualização da extensão e do formato dos grupos, assim como eventuais outliers.
Além disso, vale ressaltar que houve sobreposição entre alguns clusters, principalmente no G3, que apresenta áreas coincidentes com o G0, G2 e G4. Essa proximidade visual revela uma diferenciação menos nítida entre esses conjuntos, o que indica a existência de ações com indicadores financeiros semelhantes. Em contraste, o G1 é o único grupo sem sobreposição e geograficamente mais afastado, sinalizando uma diferenciação mais clara em relação aos demais perfis.
4.4 Relação de Risco e Retorno
Com a definição dos clusters, foi construída uma visualização que relaciona o risco e o retorno de cada papel, utilizando a volatilidade média histórica e o rendimento médio de dividendos, respectivamente. O objetivo é avaliar se determinados clusters concentram ações mais arriscadas, conservadoras ou com maior potencial de retorno. Além disso, foram adicionadas linhas tracejadas no gráfico para destacar os ativos considerados com maior atratividade, isto é, com pagamento de dividendos elevado ou baixa volatilidade.
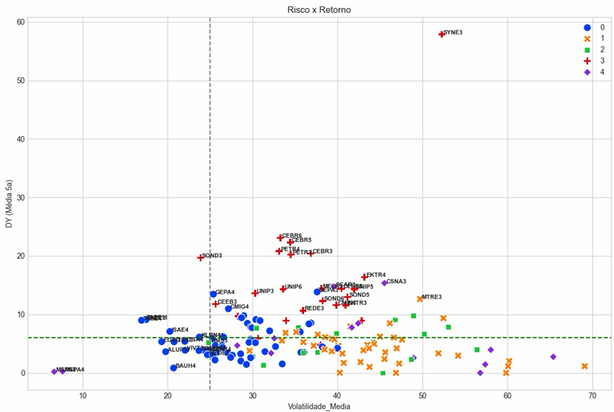
A partir dessa construção, foram criados quatro quadrantes:
- Baixo risco e baixo retorno: canto inferior esquerdo;
- Baixo risco e alto retorno: canto superior esquerdo;
- Alto risco e baixo retorno: canto inferior direito;
- Alto risco e alto retorno: canto superior direito.
Tendo em vista o objetivo de estabilidade da carteira previdenciária, o quadrante de mais interesse é o de baixo risco e alto retorno, devido ao potencial desses papéis de gerar uma renda recorrente estável.
Ao analisar o gráfico, é possível perceber que a maioria das ações elencadas apresenta alta volatilidade e pagamento de rendimentos próximo à linha de corte. Esses ativos podem se enquadrar em um perfil de investimento mais especulativo e com menor potencial de contribuição consistente para uma carteira de longo prazo.
Além disso, alguns papéis combinam rendimentos elevados com risco moderado, situando-se acima da linha horizontal e mais à direita do gráfico, sendo candidatos ideais para compor a carteira proposta.
Por fim, vale destacar a presença de outliers, com volatilidade e rendimentos muito elevados, o que indica cautela em relação ao objetivo de recorrência, pois esses valores podem refletir apenas uma situação momentânea, suscetível de se alterar ao longo do tempo.
5. Análise Pós-Clustering
5.1 Perfil dos Clusters
Após a clusterização das ações com base nas métricas discutidas anteriormente, foi possível construir um perfil para cada cluster, reunindo as características das ações que os compõem:
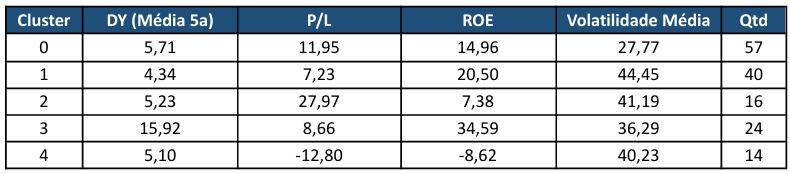
Cluster 0: Este grupo é composto por empresas que apresentam uma rentabilidade excelente, indicado pelo ROE de 22,32%, mas que são negociadas a múltiplos de preço baixos (P/L de 7,57). Esse cenário sugere uma oportunidade clássica de “valor”, onde o mercado pode estar subestimando a capacidade de geração de lucro dessas companhias. No entanto, o investidor paga o preço da instabilidade, já que este cluster possui a maior volatilidade média da tabela (43,87%). O dividend yield de 4,42% é moderado, indicando que o foco aqui é a eficiência operacional e a potencial valorização das cotas, apesar das oscilações bruscas de preço.
Cluster 1: O Cluster 1 agrupa o perfil de maior risco da amostra, caracterizado por empresas que, em média, estão operando com prejuízo, como demonstram o ROE negativo de -8,32% e o P/L de -12,76%. O fato de ainda apresentarem um Dividend Yield de 5,16% é um sinal de alerta, pois pode indicar distribuições insustentáveis feitas a partir de reservas ou dívida. Com uma volatilidade alta (40,00%) e o menor número de empresas (15), este grupo representa ativos em situações de “turnaround” ou setores em crise profunda, onde o retorno depende totalmente de uma reestruturação bem-sucedida do negócio.
Cluster 2: Este perfil identifica empresas que o mercado precifica com grande otimismo em relação ao futuro, mas que entregam resultados modestos no presente. O P/L elevado de 27,99 indica que o investidor aceita pagar caro por cada real de lucro, enquanto o ROE de apenas 7,38% mostra uma rentabilidade abaixo da média. Com uma volatilidade de 41,26%, o risco de uma correção de preços é considerável caso as expectativas de crescimento não se concretizem. É um grupo que exige cautela, pois o prêmio pago pelo ativo parece desconectado da sua eficiência operacional atual.
Cluster 3: Sendo o maior grupo da amostra (55 empresas), o Cluster 3 representa o comportamento padrão das grandes empresas consolidadas do mercado. É o perfil ideal para investidores conservadores, pois apresenta a menor volatilidade média (27,38%), oferecendo maior previsibilidade. Os fundamentos são equilibrados: um ROE saudável de 14,72%, um múltiplo P/L justo de 11,78% e um dividend yield sólido de 5,56%. São empresas que não prometem retornos explosivos, mas garantem consistência e proteção ao patrimônio no longo prazo.
Cluster 4: Este é o cluster de elite da tabela, reunindo empresas que conseguem unir eficiência máxima a uma distribuição de proventos agressiva. Com um ROE impressionante de 31,90% e o maior Dividend Yield médio (17,06%), estas companhias são máquinas de gerar valor para o acionista. O P/L de 8,65 sugere que, apesar da excelente qualidade, elas não estão excessivamente caras. A volatilidade de 36,55 é moderada para o nível de retorno oferecido, tornando este grupo o alvo principal para quem busca renda passiva sem abrir mão de fundamentos operacionais de altíssimo nível.
5.2 Ranqueamento das ações
Com os clusters definidos, o passo seguinte consistiu em ordenar as ações dentro de cada grupo, da melhor para a pior, com base nas seguintes métricas fundamentalistas: Dívida Bruta/Patrimônio Líquido, Crescimento de Receita nos últimos cinco anos, Liquidez Corrente e Payout.
No código, o ranqueamento das ações em cada cluster é realizado por meio de um sistema de pontuação multivariado, que prioriza a saúde financeira e o potencial de retorno das empresas. Para cada grupo, é calculado um score, cuja lógica de pontuação varia conforme a natureza da métrica considerada:
- No caso do endividamento, o algoritmo atribui melhores posições aos menores valores (ordem ascendente);
- Para crescimento, liquidez e distribuição de lucros, as maiores pontuações são concedidas aos maiores valores (ordem descendente).
Ao final, as ações são ordenadas pela soma dessas pontuações, resultando em uma lista na qual as primeiras posições de cada cluster representam as empresas com melhor equilíbrio entre solidez operacional e eficiência financeira.
5.3 Escolha das ações
Com o ranqueamento das ações concluído, procedeu-se à seleção dos ativos que iriam compor a carteira. Visando maior diversificação e considerando o caráter previdenciário da estratégia adotada, definiu-se que a carteira seria composta por 10 ações, número que permite adequada diversificação setorial sem comprometer o acompanhamento individual dos ativos.
Para garantir essa diversificação, foi empregado o denominado Algoritmo do Rodízio, método de construção de carteiras que evita a concentração excessiva em um único setor ou perfil de empresa. Em vez de selecionar diretamente as ações mais bem posicionadas no ranking geral, o algoritmo realiza a escolha de forma alternada entre os diferentes clusters identificados. Inicialmente, seleciona-se a ação melhor ranqueada de cada cluster; caso ainda haja espaço na carteira, o processo é repetido com as ações subsequentes de cada grupo, até que o número total de ativos seja atingido.
Esse procedimento assegura uma distribuição equilibrada entre diferentes perfis de risco e retorno, preservando a diversificação da carteira e alinhando a seleção dos ativos aos objetivos de estabilidade e recorrência característicos de uma estratégia previdenciária.
As ações selecionadas através do Algoritmo do Rodízio foram:

5.4 Cálculo de investimentos
5.4 Cálculo de investimentos
Com as ações que compõem a carteira previdenciária já definidas, procedeu-se ao cálculo da alocação percentual de cada ativo por meio do método de Ponderação Composta, aplicado a uma estratégia focada em dividendos. Esse método utiliza a relação entre o Dividend Yield (DY) e o múltiplo P/VP como critério para a definição dos pesos na carteira.
A Ponderação Composta é uma técnica de alocação de investimentos que define o peso de cada ativo combinando simultaneamente dois ou mais critérios, de modo a alcançar um equilíbrio entre eles. Neste projeto, o método integra o Dividend Yield, que representa o retorno em proventos, e o P/VP, que reflete o preço do ativo em relação ao seu valor patrimonial, resultando em um indicador único de eficiência. Essa abordagem evita a alocação excessiva em ações apenas por apresentarem dividendos elevados, mas estarem sobreprecificadas, ou, inversamente, em ações consideradas baratas que não geram renda recorrente.
Na prática, a Ponderação Composta funciona como um filtro de custo-benefício, direcionando o capital para os ativos que oferecem maior geração de renda em relação ao preço pago, contribuindo para a otimização da acumulação patrimonial no longo prazo.
Dessa forma, obtém-se a seguinte fórmula:
Para obter as respectivas porcentagens, usa-se:
Assim, resulta a seguinte tabela:
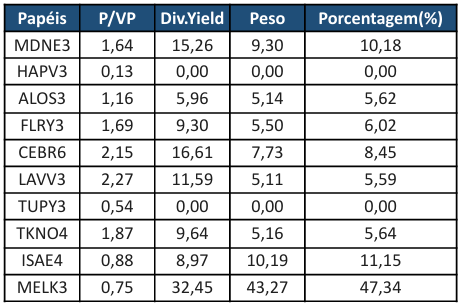
Observa-se que algumas ações receberam alocação igual a 0% na carteira. Isso ocorre porque, nesses casos, o Dividend Yield é igual a zero. Quando esse indicador assume o valor de 0,00 — como nos casos de HAPV3 e TUPY3 — significa que a empresa não distribuiu dividendos aos acionistas nos últimos 12 meses. Essa situação pode ocorrer por diferentes motivos, tais como:
- Prejuízo: a empresa não apresentou lucro líquido no período, não havendo recursos a serem distribuídos;
- Retenção de lucros: a empresa obteve lucro, mas optou por reinvestir integralmente os resultados em suas operações, visando crescimento futuro;
- Ciclo de negócios: empresas inseridas em setores de crescimento (growth) tendem a apresentar Dividend Yield reduzido ou nulo, enquanto empresas de setores maduros (value) costumam distribuir maior parcela de seus lucros.
Ao analisar especificamente as duas empresas da carteira que apresentaram Dividend Yield igual a zero, observa-se, a partir dos dados disponíveis, que ambas mantiveram um ritmo consistente de crescimento ao longo dos últimos cinco anos. Esse comportamento indica que tais empresas se enquadram em contextos de retenção de lucros e em fases específicas do ciclo de negócios. Entretanto, apesar de o preço de mercado dessas ações se apresentar atrativo, não há garantia quanto ao momento de retomada da distribuição de dividendos. Diante disso, uma alternativa conservadora seria atribuir pesos reduzidos, entre 2% e 3%, a esses ativos, assegurando uma participação mínima na carteira. Essa decisão se justifica pela solidez operacional das empresas e pela perspectiva de voltarem a distribuir dividendos relevantes no futuro.
Outro ponto identificado na composição inicial da carteira foi a elevada concentração de recursos em um único ativo, a ação MELK3, que representava aproximadamente 45% do total investido. Essa concentração decorreu do Dividend Yield excepcionalmente elevado apresentado pela empresa nos últimos 12 meses. Contudo, um nível tão alto de alocação em um único ativo aumenta significativamente a exposição a riscos específicos e à volatilidade do mercado. Assim, adotando-se um viés conservador, estabeleceu-se um limite máximo de 25% de alocação por ativo. O excedente anteriormente alocado em MELK3 foi redistribuído entre as demais ações da carteira, resultando em uma nova configuração de pesos, apresentada na tabela a seguir.
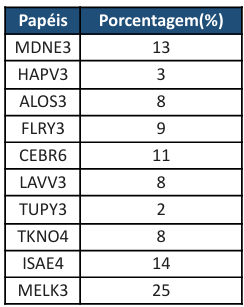
6. Teste de Carteira
Após a construção da carteira previdenciária por meio dos filtros setoriais, métricas fundamentalistas, processo de clusterização, ranqueamento e definição das ponderações dos ativos, realizou-se uma etapa de validação empírica da estratégia. Essa validação teve como objetivo verificar, com dados históricos, o comportamento da carteira ao longo do tempo em termos de rentabilidade, risco e estabilidade, complementando a análise teórica e computacional desenvolvida em Python.
Para essa finalidade, foi utilizado o simulador online SimularCarteira (https://simularcarteira.com.br), uma ferramenta de backtesting que permite simular estratégias de investimento a partir de séries históricas de preços e proventos do mercado brasileiro. O uso do simulador nesta etapa não substitui o modelo implementado em Python, mas atua como um instrumento complementar de verificação, permitindo confrontar os resultados esperados da estratégia com uma simulação prática de longo prazo.
Os parâmetros de entrada da simulação foram definidos de modo a refletir fielmente o perfil previdenciário da carteira construída no projeto. Assim, adotou-se um aporte inicial de R$ 800,00, acompanhado de aportes mensais de R$ 400,00, simulando um investidor recorrente e disciplinado. O período analisado compreende o intervalo de janeiro de 2000 a dezembro de 2025, abrangendo diferentes ciclos econômicos, regimes de juros e momentos de estresse no mercado financeiro brasileiro.
Optou-se por não realizar rebalanceamentos periódicos ao longo da simulação, com o objetivo de observar a dinâmica natural da carteira ao longo do tempo, evidenciando efeitos de concentração setorial e de ativos decorrentes exclusivamente da estratégia de seleção e ponderação adotada no código. Por outro lado, foi ativada a opção de reinvestimento automático dos proventos, coerente com a lógica previdenciária do projeto, na qual dividendos e juros sobre capital próprio são reintegrados ao patrimônio, potencializando o efeito de capitalização no longo prazo.
Adicionalmente, não foram ativadas comparações com benchmarks como CDI, Ibovespa ou inflação (IPCA) nesta etapa, uma vez que o foco da análise recai sobre o desempenho absoluto da carteira, e não sobre sua performance relativa. A partir desses inputs, o simulador forneceu métricas consolidadas de rentabilidade acumulada, retorno anualizado (CAGR), volatilidade, drawdown máximo e evolução temporal do patrimônio, as quais são analisadas criticamente na seção seguinte, à luz das decisões metodológicas implementadas no projeto em Python.
7. Análise do Teste
7. Análise do Teste
A partir dos parâmetros definidos e da execução do backtesting no simulador SimularCarteira, procede-se à análise dos resultados obtidos. O primeiro ponto a ser destacado refere-se à superação de uma limitação técnica inerente à própria ferramenta: observa-se que o simulador utilizou automaticamente o ativo TRPL4 para representar a posição originalmente definida como ISAE4, o que possibilitou a incorporação do histórico de dados desde o ano 2000. Esse ajuste garantiu maior abrangência temporal à simulação, contribuindo para a robustez da análise.
Com base nesses resultados, apresenta-se, a seguir, uma avaliação técnica estruturada a partir dos principais indicadores de desempenho da carteira.
7.1 Rentabilidade em Relação ao Período
O rendimento acumulado da carteira foi de 4,40%, com um CAGR (taxa de crescimento anualizada) de 0,98%. Isoladamente, esse resultado pode parecer modesto para uma estratégia de perfil previdenciário. No entanto, sua interpretação exige a contextualização do período analisado.
Parte relevante da carteira é composta por ações relativamente recentes, como MELK3, LAVV3 e MDNE3, cujos dados históricos estão disponíveis apenas a partir de 2020, o que limita o horizonte efetivo de análise. Ademais, o intervalo selecionado coincide com um período de juros elevados no Brasil, fator que impactou de forma significativa o setor de construção civil — setor que representa aproximadamente 46% da composição da carteira —, reduzindo o desempenho agregado no período.
7.2 Volatilidade e Risco
A volatilidade anual observada foi de 40,39%, valor considerado elevado sob a ótica de uma carteira previdenciária. A principal explicação para esse nível de risco reside na elevada concentração em empresas do setor de incorporação imobiliária, como Melnick, Moura Dubeux e Lavvi, cujas ações apresentam oscilações superiores à média do mercado.
Em contrapartida, o drawdown máximo registrado foi de -11,73%, patamar relativamente baixo quando comparado à volatilidade observada. Esse resultado sugere que, embora a carteira apresente oscilações expressivas no curto prazo, não houve quedas abruptas e persistentes ao longo do período analisado. A presença de ativos mais defensivos, como TRPL4 (ISA CTEEP) e CEBR6, contribuiu para a mitigação de perdas mais severas, exercendo um papel estabilizador na dinâmica da carteira.
7.3 Foco em Dividentos: Limitações do simulador
Observa-se que a coluna referente ao “Total em proventos” não apresenta informações claras ou não está plenamente incorporada ao cálculo do rendimento acumulado. Essa limitação é particularmente relevante, considerando que a estratégia adotada possui caráter previdenciário e é fortemente orientada à geração de renda por meio de dividendos.
Dessa forma, o retorno econômico efetivo da carteira tende a ser superior aos 4,40% indicados, uma vez que empresas como ISA CTEEP e determinadas incorporadoras, em períodos de maior lucratividade, realizam distribuições relevantes de proventos que não são integralmente capturadas apenas pela valorização da cota no simulador.
8. Considerações Finais sobre o Projeto
O presente projeto teve como objetivo desenvolver e testar uma carteira previdenciária automatizada, fundamentada em critérios quantitativos, análise fundamentalista e técnicas de aprendizado de máquina. Ao longo do trabalho, foi construído um pipeline de decisão, que abrange desde a coleta e padronização de dados financeiros, passando por filtros de qualidade, clusterização de ativos, ranqueamento multivariado, definição de ponderações e, por fim, validação empírica por meio de backtesting.
A metodologia adotada buscou reduzir a subjetividade típica dos processos tradicionais de seleção de ativos, substituindo decisões discricionárias por regras explícitas, replicáveis e economicamente justificáveis. Nesse sentido, o projeto demonstra que é possível estruturar uma estratégia previdenciária coerente utilizando ferramentas de programação, estatística e finanças quantitativas, mesmo diante das limitações inerentes aos dados disponíveis no mercado brasileiro.
8.1 Avaliação pessoal
Do ponto de vista pessoal e acadêmico, o desenvolvimento deste projeto proporcionou uma integração prática entre teoria financeira, ciência de dados e programação em Python. A implementação das etapas de filtragem, clusterização e otimização evidenciou a importância de compreender não apenas os algoritmos utilizados, mas também o significado econômico das métricas envolvidas, evitando interpretações mecanicistas dos resultados.
Além disso, a análise crítica do backtesting revelou que o desempenho de uma carteira não pode ser avaliado apenas por métricas isoladas de retorno, sendo fundamental considerar o contexto macroeconômico, o perfil setorial e as limitações das ferramentas de simulação empregadas.
8.2 Limitações e erros identificados
Algumas limitações e fragilidades foram identificadas ao longo do projeto. Em primeiro lugar, a base de dados utilizada depende de web scraping do site Fundamentus, o que impõe restrições quanto à estabilidade das informações, possíveis mudanças na estrutura do site e ausência de dados históricos completos para empresas mais recentes.
Adicionalmente, a elevada concentração setorial observada na carteira final, especialmente no setor de construção civil, revelou uma sensibilidade excessiva a ciclos econômicos específicos, refletida em níveis elevados de volatilidade. Embora essa concentração tenha sido parcialmente mitigada por ativos defensivos, ela evidencia a necessidade de mecanismos adicionais de controle de risco.
Por fim, o simulador utilizado na etapa de validação empírica apresenta limitações relevantes na contabilização dos proventos, o que pode subestimar o retorno efetivo de uma estratégia orientada à geração de dividendos.
8.3 Diagnóstico final
A carteira analisada apresenta uma estrutura híbrida, com uma base defensiva composta por setores mais perenes, como energia e saúde, enquanto seu núcleo está concentrado em ativos de crescimento e fortemente dependentes do ciclo econômico, notadamente o setor de construção civil. Essa configuração explica simultaneamente o nível elevado de volatilidade observado e o drawdown relativamente controlado no período analisado, evidenciando o papel estabilizador dos ativos defensivos.
Os resultados obtidos indicam que, embora a estratégia apresente fundamentos sólidos e coerência com uma abordagem previdenciária de longo prazo, há espaço significativo para aprimoramentos no balanceamento entre risco, retorno e estabilidade.
8.4 Possíveis caminhos, melhorias e evoluções
Como desdobramento natural do projeto desenvolvido em Python, algumas extensões metodológicas podem ser consideradas. Destacam-se, em especial: (i) a implementação de estratégias de rebalanceamento periódico, por exemplo em bases semestrais, permitindo a redistribuição de ganhos de ativos com maior valorização para aqueles com desempenho inferior, reduzindo concentrações excessivas; (ii) a redução deliberada da exposição ao setor de incorporação imobiliária, ampliando a participação de setores mais resilientes e menos cíclicos, de modo a tornar a carteira mais aderente a um perfil previdenciário de longo prazo; (iii) a incorporação de métricas adicionais de risco, como Value at Risk (VaR) e Conditional Value at Risk (CVaR), bem como a comparação sistemática com benchmarks de mercado e inflação; (iv) a internalização completa do backtesting no próprio ambiente Python, eliminando dependências externas e permitindo maior controle sobre a contabilização de proventos e custos. Em síntese, ainda que o projeto não resulte em uma carteira imediatamente pronta para uso prático, ele estabelece uma base sólida para a construção de carteiras previdenciárias quantitativas. Além disso, evidencia que a otimização de uma estratégia de longo prazo constitui um processo essencialmente iterativo, que demanda constante revisão metodológica, adaptação às condições do contexto econômico e refinamento contínuo dos modelos utilizados.