Autores: Ana Monteiro · Jayni Lima · Lucas Navis
1. Introdução
1.1 Contexto e motivação (cripto, regimes, ruído e não-linearidade)
Esse projeto foi montado com o intuito de aprofundar o nosso conhecimento do que é Fuzzy Logic e como considerar a elevada complexidade dos mercados financeiros contemporâneos se caracterizarem pela não-linearidade e forte dependência de regimes de mercado, olhando tal complexidade com enfoque no mercado de criptoativos, buscando desconsiderar abordagens clássicas de engenharia de features, onde é corriqueiramente assumido fronteiras definidas entre diferentes estados de mercado (bullish/bearish, risk-on/risk-off, etc.), e procurando utilizar a ferramenta como forma de explorar alternativas que permitam representar estados de mercado pelos intermédios, considerando incertezas advindas do fator humano do mercado.
1.2 Pergunta de pesquisa / hipótese do projeto
A principal pergunta deste projeto é: A utilização de features fuzzificadas, comparadas com features contínuas, contribuiria para uma melhor representação dos regimes de mercado e melhora na previsibilidade de retornos em criptoativos por meio de modelos supervisionados? Considerando essa inicial questão, teríamos como hipótese central de que a aplicação de lógica fuzzy à engenharia de features econômicas permitiria capturar mais adequadamente as transições graduais entre regimes de mercados, quando comparados à features contínuas tradicionais; E assim, esperar-se-ia que os modelos treinados sob dataframes fuzzificados apresentassem desempenho superior (ou ao menos maior robustez) quando comparados a dataframes sem devida fuzzificação.
1.3 Objetivo Geral
O objetivo geral deste projeto é desenvolver e avaliar um pipeline de engenharia de features baseado em lógica fuzzy aplicado à modelagem supervisionada de mercados de criptoativos, com foco na identificação de regimes de risco e na previsão de retornos futuros por meio de machine learning.
1.4 Objetivos Específicos
- Construir features financeiras tradicionais (trend, volatilidade, macro, etc.);
- Aplicação de fuzzificação por funções de pertinência;
- Comparar desempenho de modelos com o dataset contínuo x dataset fuzzificado;
- Avaliação dos resultados preditivos e econômicos.
1.5 Escopo e recortes (universo, horizonte, período, limitações)
No escopo deste projeto, consideramos as seguintes considerações:
- O universo de ativos foram escolhidos para englobar todo nível de risco, indo desde renda fixa até criptomoedas;
- O horizonte de tempo foi de cinco anos (ou seja, de 2021 até hoje em dia), considerando que cada linha do .csv dos dados seja uma representação dos preços dos ativos listados dia-a-dia;
- O estudo foca na utilização de um único algoritmo de machine learning (CatBoost), fazendo com que os resultados obtidos não devam ser generalizados sem análises adicionais.
1.6 Visão geral do pipeline
O pipeline desenvolvido neste projeto pode ser explicado por um passo-a-passo, desde a análise e limpeza dos dados até projeção futuro via machine learning:
- O pipeline começa pela padronização dos dados históricos dos 10 maiores criptoativos, organizados de forma temporalmente consistente, considerando uma janela de cinco anos atrás, até hoje em dia. A partir desses dados, são construídas juntamente séries de preços e retornos, que servem como base para o cálculo de variáveis quantitativas relacionadas ao comportamento do mercado;
- Nessa segunda etapa são consideradas features contínuas (drawdown, índice de fear and greed, etc.) que capturam diferentes dimensões do risco referente a ortogonalidade entre elas, fazendo com que essas features contínuas sejam transformadas em graus de pertinência pelo processo de fuzzificação;
- E por fim, os resultados são consolidados em um dataframe final pela filtração de considerar apenas features com um nível de correlação menor ou igual à 0.25, e assim alimentar um modelo de machine learning CatBoost para previsão de retornos sobre os criptoativos, considerando manter alinhamento temporal já padronizado e evitar leakage.
2.Fundamentação e conceitos essenciais
2.1 Séries temporais financeiras e “leakage” (por que é crítico aqui)
Dados financeiros são, por natureza, organizados como séries temporais, nas quais cada observação depende do histórico anterior. Nesse contexto, o que é ‘data leakage’ seria de, diretamente ou indiretamente, considerar informações especulativas/futuras na construção de variáveis ou modelos que essencialmente podem apenas operar com dados disponíveis até neste momento (como o caso de qualquer modelo preditivo pro mercado financeiro), e isso pode ser um problema crítico considerando a possibilidade de gerar resultados muito artificiais, enviesados ao otimismo e sendo assim, inviáveis na prática.
Tendo esse risco de leakage em mente, consideramos ter como forma de mitigar tal risco com o uso de janelas móveis retrospectivas (momentum de 7d, vol de 30d, etc.), ordenação e validação temporal, que estrita os dados por data e ativo (assim, respeitando a causalidade de eventos), fazendo com que os regimes de risco possam ser interpretados como sinais genuínos.
2.2 O que são e relevância da engenharia de features em mercados (tendência, vol, stress, qualidade, macro)
A engenharia de features consiste no processo de transformar dados brutos em variáveis informativas, e quando aplicadas ao mercado financeiro, seria de extrema importância organizar features de forma que desconsidere o ruído e a alta variabilidade que costuma estar diluído nessas informações. Nisso, consideramos organizar em categorias economicamente relevantes:
- Tendência: captura a direção predominante do preço, refletindo o curto prazo;
- Volatilidade: representa a intensidade do delta e o nível de incerteza do mercado como um todo;
- Stress (drawdown): calcula perdas acumuladas em relação a máximos recentes, associadas a eventos adversos;
- Qualidade: avaliação a relação entre risco e retorno considerado janelas móveis;
- Macro: indicadores como fear and greed index (FGI) mostram qual seria o sentimento do mercado.
2.3 Multicolinearidade e seleção de variáveis (por que controlar correlação)
Em contexto de mercados financeiros, é comum que diferentes variáveis carreguem informações semelhantes, fazendo com que resulte em alta correlação entre features, sendo esse fenômeno ser conhecido como multicolinearidade. Ter essa redundância excessiva entre features faz com que seja difícil a interpretação dos resultados e, no geral, amplificar ruídos já preexistentes. Nisso, consideramos como forma de mitigar a multicolinearidade a filtragem de features com níveis de correlação grandes. A filtragem acaba sendo simples, sendo primeiramente um cálculo de correlação entre das variáveis entre si, e filtrando qualquer variável com um nível de correlação maior ou igual à 0.25, assim fazendo com que reforçemos a ortogonalidade das features e mitiguemos a multicolinearidade.
2.4 Lógica fuzzy aplicada à Features (intuição + porque pode ajudar)
A lógica fuzzy aplicada à engenharia de features faz com que o processo de fuzzificação das features transforme variáveis contínuas em graus de pertinência a categorias linguísticas (i.e. ‘volatilidade alta’, ‘tendência neutra’, etc.), e essa abordagem é devidamente adequada a mercados financeiros, considerando que transições raramente ocorrem de forma abrupta. No projeto, as funções de pertinência (como triangulares, gaussianas) são utilizadas para mapear indicadores quants em estados fuzzy, onde o resultado é uma representação mais alinhada à interpretação econômica do risco e mais limpa a ruídos extremos.
2.5 Backtest e validação temporal
O backtest temporal aqui é uma etapa central, onde procuramos fazer com que o backtest respeite a ordem cronológica dos dados e assim, simular o uso do modelo em tempo real. Assim fazendo com que a verificação da estabilidade e coerência dos regimes em relação ao risco ao longo do tempo e movimentos de preços sejam palpáveis, onde assim, também preparamos o terreno para o modelo de machine learning mais para frente.
3.Dados e construção do dataset
3.1 Fontes e universo (ativos, preços/retornos, variáveis macro como FGI, etc.)
O universo de ativos é composto pelas dez principais criptomoedas (BTC, ETH, etc.), selecionadas por representarem diferentes níveis de liquidez, volatilidade e maturidade dentro do ecossistema cripto. Os dados de preços consistem em séries históricas diárias abrangendo cinco anos (2021-hoje). Para cada ativo, são consideradas informações de mercado como preços de abertura, máxima, mínima, fechamento e volume negociado (OHLCV), dados esses coletados pela Binance e Yahoo Finance. Além desses dados base, consideramos utilizar também informações macro e de sentimento (FGI). A partir dos preços de fechamento, são calculados os retornos diários (que vão ser a base para a construção tanto das features quanto do alvo preditivo).
3.2 Tratamento e padronização (datas, tickers, missing, alinhamento)
Após a coleta de dados, eles passaram por um processo de tratamento e padronização, visando garantir coerência na linha do tempo e valores que possam ser estatisticamente integrados. Valores ausentes foram tratados com métodos conservadores (como fill.na()), sempre respeitando a ordem temporal, e assim evitando a introdução de informações incoerentes. Os tickers dos ativos foram formatados buscando consistência e padronização, facilitando assim o processo de agregação, filtragem e junção de dados .csv como um todo. E por fim, os dados foram ordenados por ativo e data para considerarmos uma estrutura propícia para o cálculo de janelas móveis, e para mais tarde, validação temporal.
3.3 Definição do target (horizonte, construção t→t+1, discretização/labels)
O target do modelo é definido em base de um horizonte de previsão de t + 1, refletindo um cenário realista de decision making no contexto de mercados financeiros. O target contínuo corresponde ao log do retorno do dia seguinte, calculado a partir dos preços de fechamento do ativo. A discretização do target pode ser considerada pela transformação desse log do retorno em classes, onde o valor 1 se equivalem para retornos positivos acima do limiar; e valor 0 para retornos neutros/menor que zero. Reforçando que, nenhuma informação em t + 1 seja utilizada no cálculo das features em t, e assim eliminando qualquer risco de leakage no modelo.
3.4 Split temporal / protocolo de validação (holdout temporal e/ou walk-forward)
Diante o fato de que dados financeiros apresentam forte dependência temporal, não estacionariedade e mudanças estruturais de regime ao longo do tempo, decidimos adotar ao nosso projeto um split estritamente temporal, no qual os dados são divididos de forma cronológica, assegurando que o conjunto de teste contenha apenas observações posteriores ao conjunto de treino. Nisso tudo, se adequando ao contexto do mercado de cripto, empregamos a estratégia de validação walk forward, onde nesse esquema o modelo é treinado em uma janela histórica inicial e testado em um período subsequente, com a janela de treino sendo deslocada ao longo do tempo. Esse procedimento permite avaliar o desempenho do modelo sob diferentes condições de mercado e simula de forma mais realista o processo de decision making fora da amostra temporal
3.5 Ferramentas e ambiente
As principais ferramentas empregadas no desenvolvimento deste projeto consistem em bibliotecas da linguagem Python amplamente utilizadas em aplicações quantitativas e científicas, dentre as quais destacam-se pandas e numpy para manipulação e análise de dados, matplotlib.pyplot e seaborn para visualização, yfinance e ccxt para coleta de dados de mercado, além de scikit-learn e CatBoost para modelagem e machine learning.
A organização do projeto segue uma estrutura modular dentro do Github, com separação clara entre dados brutos, dados processados, scripts de feature engineering, módulos de modelagem e resultados. Essa estrutura nos oferece a reprodutibilidade e escalabilidade do pipeline, fazendo com que a manutenção do código e futuras extensões sejam fáceis de serem implementadas.
4. Engenharia de Features “clássicas” (contínuas)
A etapa de engenharia de features “clássicas” consiste em transformar séries de preços (OHLCV) e variáveis exógenas (macro) em variáveis quantitativas contínuas capazes de representar, de forma resumida e informativa, diferentes dimensões do comportamento do preço. O objetivo central é construir um conjunto de variáveis que capturem dinâmicas recorrentes do mercado, reduzindo ruído, permitindo comparação entre ativos e facilitando o treinamento de modelos preditivos para retorno futuro.
Neste projeto, a engenharia de features foi organizada em tópicos (trend, volatilidade, stress, qualidade relativa e macro), pois mercados financeiros são multifatoriais e, na prática, diferentes métricas “enxergam” regimes distintos. Em criptomoedas, essa organização é especialmente relevante devido à alta volatilidade, mudanças de regime frequentes e forte assimetria de retornos. Assim, as features foram definidas de forma a representar a direção e persistência de preço (tendência), a incerteza (volatilidade), a severidade e persistência de perdas (stress), a qualidade do retorno ajustado ao risco e força relativa (qualidade relativa) e o contexto macro/sentimento (macro).
4.1 Lógica das features
A motivação para trabalhar com tópicos é que um mesmo movimento de preço pode ter causas e leituras diferentes. Por exemplo, uma alta recente pode representar (i) início de uma tendência (momentum), (ii) efeito de um choque pontual com alta volatilidade (risco), ou (iii) apenas “reversão” após drawdown profundo (stress). Logo, usar somente uma métrica tende a ser insuficiente e pode induzir o modelo a conclusões instáveis. Ao separar em tópicos, o projeto garante cobertura conceitual: cada grupo explica uma dimensão distinta do mercado.
Em termos práticos, a lógica de tópicos atende a dois objetivos. Primeiro, reduz redundância, pois features dentro do mesmo tópico geralmente carregam informação semelhante e, portanto, correm mais risco de alta correlação. Segundo, melhora a interpretabilidade, já que cada bloco responde a uma pergunta: “o ativo está em tendência?”, “o risco está alto?”, “o ativo está sob stress?”, “o retorno tem qualidade?”, “o sentimento macro está favorável?”.
4.1.1 Regime de tendência (bull / bear / sideways)
O regime de tendência descreve o estado direcional do mercado, isto é, se o preço apresenta uma trajetória persistente de alta, queda ou movimento lateral. Em cripto, esse regime pode surgir por narrativas (adoção, halving, notícias), fluxo de capital e comportamento coletivo. O ponto central é que, quando o mercado está em tendência, movimentos tendem a ser persistentes por algum tempo, de modo que retornos acumulados recentes e medidas de inclinação podem carregar informação não só sobre curto prazo, mas também de médio prazo.
- Bull regime (tendência de alta): prevalecem retornos acumulados positivos em janelas curtas e médias; médias móveis curtas tendem a ficar acima das longas; e a inclinação do log-preço tende a ser positiva. Nessa fase, o mercado pode apresentar correções pontuais sem perder a direção estrutural.
- Bear regime (tendência de baixa): retornos acumulados negativos e médias curtas abaixo das longas; inclinação negativa; e aumento de sensibilidade a choques. Em bear markets de cripto, quedas podem ser rápidas e profundas, com picos frequentes.
- Sideways regime (lateralização): retornos acumulados próximos de zero, alternando sinais; médias móveis próximas entre si; inclinação próxima de zero. É um regime em que estratégias baseadas apenas em momentum tendem a gerar falsos sinais.
Como o tópico Trend captura isso: features de momentum, diferença de EMAs e slope foram escolhidas justamente para medir direção (alta/baixa), persistência (curto e médio prazo) e consistência do movimento (inclinação).
4.1.2 Regime de volatilidade (low-vol / high-vol / transition)
O regime de volatilidade descreve o nível e a estabilidade do risco. Em cripto, volatilidade não é apenas ruído: ela sinaliza mudanças no comportamento do mercado, aversão ao risco, momentos de alavancagem/força compradora e episódios de atenção. Em vários períodos, a direção (tendência) pode permanecer positiva, mas a volatilidade aumenta significativamente, indicando um ambiente em que o risco de reversão e de perdas abruptas cresce.
- Low-vol regime (volatilidade baixa): movimentos diários mais contidos; menor dispersão de retornos; geralmente associado a períodos de consolidação e menor “alavancagem emocional”. Pode anteceder grandes movimentos (compressão).
- High-vol regime (volatilidade alta): grandes oscilações diárias; retornos extremos; aumento de gaps e movimentos intradiários; típico de choques de notícia, fases de euforia/pânico ou transições de tendência.
- Transition regime (mudança de vol): não é apenas “vol alta”, mas sim volatilidade instável (vol-of-vol). Esse regime é relevante porque sinaliza que o mercado está mudando de comportamento, muitas vezes antes de mudanças claras de tendência.
Como o tópico Vol captura isso: medidas de volatilidade realizada (std dos retornos), proxies por range (ATR%, Parkinson) e medidas de instabilidade (vol-of-vol). A ideia é capturar tanto o nível de risco quanto sua mudança ao longo do tempo.
4.1.3 Regime de stress (normal / stress / crise prolongada)
O regime de stress é diferente do regime de volatilidade. Volatilidade alta pode ocorrer em alta e em queda; stress, por definição, está ligado a perda acumulada e deterioração do patrimônio, medido por drawdowns e caudas negativas. Em cripto, regimes de stress são críticos porque o mercado pode passar por quedas profundas e longas, com recuperação incerta. Assim, medir stress ajuda a representar “o quão machucado” o ativo está, mesmo que haja algum momentum curto positivo.
- Normal regime: drawdown próximo de zero (preço perto do pico recente), sem perdas acumuladas relevantes.
- Stress regime: drawdown negativo significativo, indicando que o ativo caiu de um pico recente; geralmente acompanhado de deterioração do sentimento e piora do retorno ajustado ao risco.
- Crise prolongada: além do drawdown grande, observa-se duração de drawdown elevada (tempo longo sem recuperar o pico), indicando que não se trata apenas de um choque rápido, mas de um regime ruim persistente.
Como o tópico Stress captura isso: drawdown atual e máximo drawdown capturam magnitude; CVaR/pior retorno capturam cauda; duração do drawdown captura persistência do regime ruim.
4.1.4 Regime de qualidade do retorno (eficiente / frágil / assimétrico)
O regime de qualidade descreve se os retornos do ativo são “bons” no sentido de compensarem o risco tomado e se são consistentes. Dois ativos podem ter o mesmo momentum, mas qualidade distinta: um pode subir com baixa volatilidade e perdas pequenas (alta qualidade), enquanto outro pode subir com volatilidade muito elevada e quedas bruscas (baixa qualidade). Em cripto, onde caudas são grandes, essa distinção é importante.
- Regime eficiente: retorno médio relativamente bom para o nível de risco; Sharpe/Sortino/IR melhores; downside risk controlado.
- Regime frágil: retorno positivo, mas risco desproporcional; métricas ajustadas ao risco baixas; maior chance de reversão por instabilidade.
- Regime assimétrico: retorno pode parecer bom, mas perdas negativas são mais severas que ganhos (Sortino piora mais que Sharpe), indicando assimetria desfavorável.
Como o tópico Qualidade relativa captura isso: métricas ajustadas ao risco (Sharpe, Sortino, IR), força relativa e medidas de persistência (autocorrelação) ajudam a medir consistência e eficiência.
4.1.5 Regime macro/sentimento (fear / neutral / greed e mudanças)
O regime macro/sentimento representa um estado agregado do mercado que pode afetar simultaneamente vários ativos. No caso deste projeto, foi utilizado o Fear & Greed Index (FGI)
como proxy de sentimento. A motivação é que, em cripto, comportamento coletivo e “humor de mercado” podem amplificar movimentos, principalmente em fases extremas.
- Fear (medo): aversão ao risco, maior chance de vendas forçadas e volatilidade em quedas; costuma coincidir com regimes de stress.
- Neutral: sentimento intermediário, sem direção clara; pode estar associado a consolidação.
- Greed (ganância): maior apetite ao risco, possíveis altas aceleradas; também pode sinalizar excesso (risco de correção).
Além do nível do FGI, as transformações de mudança e instabilidade (variação, z-score, volatilidade do FGI) ajudam a capturar transições de regime, que são relevantes porque, muitas vezes, a mudança de sentimento antecede mudança de volatilidade e tendência.
Como o tópico Macro captura isso: nível do FGI mede “estado”; mudança do FGI mede transição; z-score e vol do FGI medem extremos e instabilidade.
4.2 Feature set inicial
A definição do feature set inicial constituiu uma etapa fundamental do projeto. O objetivo dessa etapa não foi maximizar complexidade ou quantidade de variáveis, mas sim construir um conjunto inicial econômica e tecnicamente consistente, alinhado aos principais mecanismos que explicam o comportamento dos preços de ativos financeiros, especialmente no contexto de criptomoedas.
A seleção foi orientada por literatura de finanças quantitativas e por práticas consolidadas em modelos de previsão de retornos e regimes de mercado, priorizando métricas interpretáveis, amplamente utilizadas e calculadas exclusivamente a partir de informações disponíveis até o instante t, evitando qualquer forma de vazamento de informação. Além disso, a decisão dessas features considerou três critérios centrais: 1) Fundamentação econômica clara, isto é, cada variável deveria representar um conceito amplamente discutido na literatura financeira (como tendência, risco ou stress); 2) Simplicidade e interpretabilidade, privilegiando métricas conhecidas e amplamente utilizadas no mercado e em estudos acadêmicos; 3) Viabilidade operacional, considerando estabilidade estatística, disponibilidade histórica dos dados e facilidade de replicação.
Com base nesses critérios, optou-se por iniciar o projeto com um conjunto reduzido, porém abrangente, de features contínuas clássicas, organizadas principalmente nos eixos de tendência, volatilidade, stress, qualidade relativa e macroeconômico:
4.2.1 Features de tendência
O primeiro grupo de features foi dedicado à captura da direção e persistência do movimento de preços. A motivação para incluir múltiplas métricas de tendência está associada ao fato de que movimentos direcionais podem se manifestar em diferentes horizontes temporais e com diferentes intensidades. As features escolhidas foram:
- mom_7d (Momentum 7 dias): é o retorno acumulado dos últimos 7 dias. Na prática, mede se o preço vem “andando para cima ou para baixo” recentemente e com que intensidade (sinal de tendência de curto prazo).
- mom_30d (Momentum 30 dias): é o retorno acumulado dos últimos 30 dias. Na prática, mede a tendência em horizonte mais longo, filtrando parte do ruído diário e capturando movimentos mais persistentes.
- ema_diff (Diferença de EMAs): é a diferença entre duas médias móveis exponenciais (uma mais curta e outra mais longa). Na prática, mede o “gap” entre curto e longo prazo: quando é positivo e crescente, sugere tendência de alta; quando negativo, sugere tendência de baixa.
- slope_30d (Inclinação 30 dias): é o coeficiente angular de uma regressão do preço (ou log-preço) ao longo dos últimos 30 dias. Na prática, mede a “força” e a velocidade da tendência: quanto maior em módulo, mais forte e consistente é o movimento.
Essas métricas permitem capturar tanto movimentos de curto prazo (7 dias) quanto tendências mais persistentes (30-60 dias). O uso combinado de momentum simples, diferenças de médias móveis e inclinação da série busca representar não apenas o sinal direcional, mas também a aceleração e a consistência do movimento de preços ao longo do tempo.
4.2.2 Features de volatilidade
Além da direção dos preços, o nível e a dinâmica do risco são componentes essenciais para caracterizar o ambiente de mercado. Por esse motivo, o conjunto inicial incluiu múltiplas métricas de volatilidade, calculadas em diferentes janelas e sob diferentes metodologias, de modo a capturar tanto a intensidade quanto a estabilidade do risco. As features consideradas foram:
- vol_7d (Volatilidade 7 dias): é o desvio-padrão dos retornos dos últimos 7 dias. Na prática, mede o quanto o ativo “chacoalha” no curto prazo (instabilidade recente).
- vol_30d (Volatilidade 30 dias): é o desvio-padrão dos retornos dos últimos 30 dias. Na prática, mede o nível de risco mais “estrutural” recente, menos sensível a poucos dias extremos.
- atrp_14 (ATR percentual 14 dias): é o Average True Range (faixa média de variação diária incluindo gaps), normalizado pelo preço. Na prática, mede a amplitude típica de movimento do preço por dia, capturando risco de “range” (não só retorno de fechamento).
- idio_vol_30d (Volatilidade idiossincrática 30 dias): é a parte da volatilidade do ativo que não é explicada por um fator comum (mercado/benchmark), dependendo de como vocês modelaram. Na prática, mede o risco “próprio” do ativo, não o risco do mercado como um todo.
Essas features permitem avaliar não apenas a dispersão dos retornos, mas também a magnitude dos movimentos intradiários e o risco específico do ativo, aspectos particularmente relevantes em mercados com alta variabilidade e episódios frequentes de instabilidade.
4.2.3 Features de stress
Além da volatilidade, foi considerada essencial a inclusão de métricas que captam episódios de perda extrema e stress acumulado, que não são plenamente representados por medidas tradicionais de dispersão. Duas variáveis principais foram escolhidas:
- max_dd_30d (Máximo drawdown 30 dias): é a maior queda do pico ao fundo nos últimos 30 dias. Na prática, mede o pior “tombo” recente, captura risco de cauda e perda extrema, não apenas oscilação média.
- drawdown_90d (Drawdown 90 dias): é a queda acumulada em relação ao maior preço dentro de 90 dias (ou o drawdown atual nessa janela, conforme cálculo). Na prática, mede se o ativo está “afundado” vs. o topo recente e o tamanho dessa crise.
Essas métricas refletem a profundidade das perdas sofridas pelo ativo em janelas recentes, sendo fundamentais para caracterizar regimes de crise. Diferentemente da volatilidade, que mede dispersão em torno da média, o drawdown captura assimetria negativa, eventos extremos e persistência de perdas, aspectos críticos para avaliação de risco em mercados não lineares.
4.2.4 Features de qualidade relativa
O grupo de qualidade relativa foi incluído com o objetivo de mensurar o retorno ajustado ao risco e a força relativa do ativo ao longo do tempo. Essas métricas permitem avaliar se retornos elevados estão sendo obtidos de forma consistente ou apenas como resultado de maior exposição ao risco. As variáveis selecionadas foram:
- ir_30d (Information Ratio 30 dias): é o retorno excedente (vs. referência) dividido pelo risco desse excedente (tracking error). Na prática, mede eficiência: se o ativo entrega retorno “bom” de forma consistente, ajustado pelo risco de descolar do benchmark.
- rs_30d (Relative Strength 30 dias): compara o desempenho do ativo contra um referencial (mercado ou cesta) no horizonte de 30 dias. Na prática, mede “força relativa”: se o ativo está performando melhor ou pior que o resto.
Essas features são amplamente utilizadas em finanças quantitativas para distinguir movimentos sustentáveis de retornos espúrios, oferecendo uma dimensão adicional de avaliação da eficiência do ativo sob diferentes regimes de mercado.
4.2.5 Features macro e de sentimento
Com o objetivo de capturar o ambiente macroeconômico e o sentimento agregado do mercado, reconhecendo que o comportamento dos preços de criptoativos é fortemente influenciado por fatores exógenos e por mudanças no apetite ao risco dos investidores, a principal variável considerada nesse grupo foi:
- fgi (Fear & Greed Index): é um indicador agregado de sentimento (medo vs ganância) calculado a partir de métricas do mercado (volatilidade, momentum, volume, etc.). Na prática, funciona como proxy de regime macro/sentimento: níveis baixos sugerem aversão a risco; níveis altos sugerem apetite a risco.
O FGI sintetiza informações relacionadas a volatilidade, momentum, volume e sentimento de mercado, funcionando como um proxy de regimes “risk-on” e “risk-off”. Sua inclusão no conjunto inicial teve como objetivo fornecer ao modelo um sinal agregado de contexto de mercado, complementar às métricas puramente baseadas em preços.
5. Análise de correlação e problemas encontrados
A etapa de correlação foi conduzida para reduzir redundância informacional entre as variáveis explicativas (features) e, com isso, construir um conjunto mais “limpo” para o modelo. Em termos práticos, quando duas features são muito correlacionadas, elas tendem a carregar o mesmo sinal (ou sinais muito parecidos), o que aumenta o risco de o modelo “aprender duas vezes a mesma coisa”. Isso costuma gerar instabilidade, maior sensibilidade a ruído e resultados menos robustos fora da amostra (out-of-sample), especialmente em séries financeiras, que já são naturalmente ruidosas e não estacionárias.
Além disso, como o projeto compara features contínuas vs. features fuzzyficadas, manter um conjunto com baixa correlação ajuda a evitar que a fuzzyficação “multiplique” o mesmo conteúdo. Por exemplo: se duas features contínuas já são muito correlacionadas, ao fuzzyficar ambas (virando várias colunas de pertinência), o modelo pode ficar com um bloco grande de variáveis altamente redundantes, o que piora a interpretabilidade e pode prejudicar a generalização.
5.1 Fundamento teórico
A correlação utilizada foi a correlação de Pearson, que mede a associação linear entre duas variáveis. Para duas features X e Y, a correlação é dada por:
Em que cov(X,Y) é a covariância e σX, σY são os desvios-padrão. O coeficiente varia de -1 a
A correlação varia de a , em que valores próximos de indicam forte relação linear positiva, valores próximos de indicam forte relação linear negativa, e valores próximos de indicam baixa relação linear.
Para o projeto, o critério não foi “correlação positiva apenas”, mas sim o uso de correlação em valor absoluto: .
5.2 Metodologia aplicada (como foi feito no código)
A metodologia aplicada seguiu um fluxo padronizado, replicável e consistente com boas práticas em dados tabulares financeiros:
- Base utilizada. A correlação foi calculada sobre o dataset de features contínuas (conjunto inicial), no formato painel (linhas por Date–Ticker), garantindo que as correlações refletissem o comportamento das variáveis ao longo do tempo e entre ativos.
- Exclusão de colunas não elegíveis. As colunas de identificação (Date e Ticker) foram excluídas do cálculo, pois não são variáveis numéricas explicativas. Além disso, a variável ret_1d foi marcada como “DROP_ALWAYS” no filtro por ser uma medida muito próxima do próprio retorno diário e, dependendo de como o target é construído no modelo, poderia aumentar risco de redundância e ruído (além de não ser um regime em si, mas um movimento pontual).
- Cálculo da matriz de correlação absoluta. A matriz foi calculada com Pearson e transformada em valor absoluto, e a diagonal principal foi zerada para facilitar a interpretação.
- Avaliação visual (heatmap). Para interpretação e comunicação no relatório, a matriz foi visualizada via heatmap. No gráfico, cores mais “quentes” indicam correlações mais altas; e foi adotada a convenção adicional de marcar em cinza as células com ∣corr∣≤0,10, apenas como referência visual de correlação muito baixa ou ideal.
5.3 Resultados da correlação no conjunto inicial
Com o objetivo de avaliar o grau de redundância entre as variáveis do conjunto inicial, foi calculada a matriz de correlação de Pearson entre todas as features numéricas. A visualização por heatmap permite identificar padrões de associação linear entre pares de variáveis, destacando grupos de features que capturam dimensões semelhantes do comportamento do mercado. Para facilitar a leitura, adotou-se uma marcação adicional em cinza para correlações muito baixas (em valor absoluto), isto é, ∣corr∣≤0,10, de modo a evidenciar regiões do mapa com baixa relação linear.
A Figura 1 apresenta o heatmap do conjunto inicial e evidencia, principalmente, blocos de correlação elevada dentro dos tópicos (por exemplo, tendência e volatilidade), o que é esperado em séries financeiras: métricas derivadas do mesmo preço, em janelas próximas ou com lógicas semelhantes, tendem a se mover de forma parecida. Observa-se também que variáveis de stress e sentimento podem apresentar correlação relevante com medidas de risco e tendência, refletindo o fato de que períodos de queda e aversão ao risco costumam ocorrer simultaneamente. Esses padrões reforçam que, apesar de economicamente coerentes, diversas features iniciais carregavam sinais parcialmente sobrepostos, motivando a etapa seguinte de filtragem por limite máximo de correlação.
**Figura 1** – Heatmap da matriz de correlação do conjunto inicial de features por corr de Pearson.
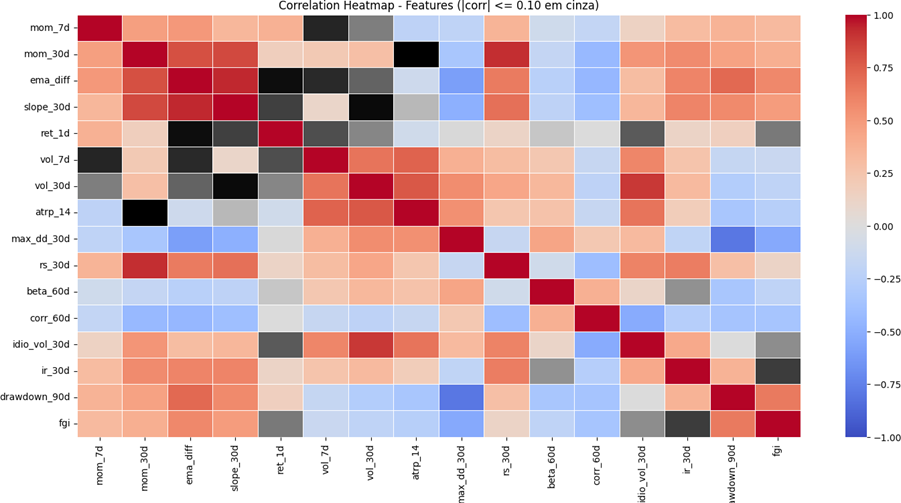
Info
Legenda: A escala de cores varia de -1 (azul) a +1 (vermelho). As células em cinza destacam pares com correlação muito baixa (mais próximas a 0).
A matriz de correlação do conjunto inicial evidenciou um comportamento esperado em séries financeiras: muitas features carregavam fatores comuns, o que gera correlações elevadas. Observou-se principalmente:
- Bloco de tendência (trend) com correlações altas entre si. Features como mom_7d, mom_30d, ema_diff e slope_30d tendem a se mover juntas, pois todas representam a mesma ideia central: direção e persistência recente do preço. Isso aparece no heatmap como um agrupamento com correlações elevadas dentro desse conjunto.
- Bloco de volatilidade (vol) também altamente correlacionado. Variáveis como vol_7d, vol_30d e atrp_14 são diferentes formas de medir dispersão/magnitude de variações. É comum que se correlacionem, porque capturam o mesmo fenômeno (risco de curto prazo), apenas com janelas e normalizações distintas.
- Stress e drawdown apresentam relação relevante com volatilidade e, em alguns casos, com tendência. Métricas como max_dd_30d e drawdown_90d capturam quedas acumuladas e episódios extremos. Em mercados com caudas pesadas, drawdown costuma se associar com períodos de maior volatilidade; por isso, é esperado que não sejam totalmente ortogonais.
- Macro/sentimento (FGI) pode se correlacionar com regimes de risco. O índice fgi reflete sentimento agregado do mercado, que frequentemente piora em períodos de queda e stress. Por esse motivo, é plausível que apareçam correlações relevantes entre fgi e variáveis de stress ou tendência, dependendo da amostra.
Em síntese, o heatmap mostrou que o conjunto inicial era informativo, mas excessivamente redundante sob a restrição exigida pelo projeto. Em outras palavras: as features faziam sentido economicamente, porém várias delas diziam a mesma coisa do ponto de vista estatístico.
5.4 Teste de limites e problema prático encontrado (0.10 - 0.50 - 0.25)
A etapa de filtragem por correlação teve como objetivo reduzir redundâncias e evitar que o modelo fosse alimentado por variáveis que carregavam a mesma informação. Como as features foram construídas a partir de transformações do mesmo ativo (retornos e preços) e, em muitos casos com janelas próximas, era esperado que parte relevante do conjunto inicial apresentasse correlação elevada. Por isso, a definição do limiar máximo de correlação foi tratada como uma decisão metodológica central: um limite muito restritivo poderia inviabilizar a representatividade por tópico (tendência, volatilidade, stress, qualidade relativa e macro), enquanto um limite muito permissivo comprometeria o propósito do controle de multicolinearidade e tornaria a seleção pouco informativa, desviando do objetivo do projeto.
5.4.1 Limite muito rígido: max ∣corr∣ ≤ 0.10
A escolha inicial de 0,10 foi motivada por um critério mais “conservador”, buscando manter apenas variáveis praticamente ortogonais (ou quase independentes no sentido linear). Entretanto, ao aplicar o critério ao conjunto inicial, o resultado foi excessivamente restritivo: nenhuma combinação viável conseguiu manter simultaneamente o limite de correlação e pelo menos uma feature por tópico. Esse resultado não indica que as features estavam erradas, mas sim que, em dados financeiros, especialmente em cripto, existe forte presença de fatores comuns, pois o mercado anda junto, o que torna 0,10 um patamar muitas vezes impraticável para um conjunto pequeno de variáveis clássicas.
5.4.2 Limite muito permissivo: max ∣corr∣ ≤ 0.50
Diante da inviabilidade do limite de 0,10, testou-se um limiar significativamente mais flexível (0,50), com o objetivo de verificar se seria possível obter um conjunto minimamente completo (com cobertura por tópico) sem perder totalmente o controle de redundância. Nesse cenário, foi possível reter um número maior de variáveis, com quatro features permanecendo elegíveis:
Figura 2: Matriz de correlação do conjunto filtrado (exemplo com 4 features)
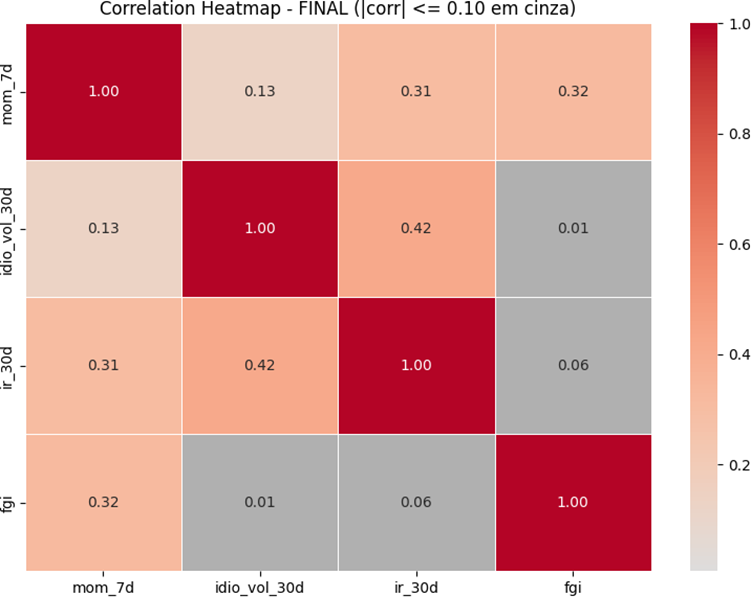
Info
Legenda: A escala de cores varia de -1 (azul) a +1 (vermelho). As células em cinza destacam pares com correlação muito baixa, isto é, próximo a 0.
Esse conjunto foi considerado um avanço porque atingia múltiplos tópicos e preservava interpretação econômica. No entanto, o limite de 0,50 foi classificado como alto demais para o objetivo do trabalho, pois ainda permite redundância relevante. No próprio heatmap final, por exemplo, aparece correlação moderada entre idio_vol_30d e ir_30d (≈ 0,42) e entre mom_7d e ir_30d (≈ 0,31).
5.4.3 Limite intermediário (definitivo do projeto): max∣corr∣ ≤ 0.25
Como solução, adotou-se um limite intermediário de 0.25: suficientemente rigoroso para reduzir redundância, mas não tão extremo a ponto de inviabilizar o modelo. Entretanto, ao aplicar o limite de 0,25 no conjunto inicial, apenas duas features conseguiram passar (representando essencialmente tendência e volatilidade), e as features de macro, stress e qualidade relativa falharam por não existirem candidatos que respeitassem o limite em conjunto com as já selecionadas.
Nesse sentido, concluiu-se que o problema não estava apenas no limiar, mas também na composição do universo inicial de variáveis, que era relativamente pequeno e altamente correlacionado entre si dentro dos tópicos. Assim, o limite de 0,25 foi mantido como referência metodológica, por ser um meio termo e suficiente para reduzir redundâncias, mas ficou claro que seria necessário ampliar o conjunto de features para que o filtro pudesse selecionar alternativas menos relacionadas sem sacrificar a cobertura por tópico. A estratégia foi: aumentar o universo de features, criando novas métricas (extras) por tópico, com maior chance de capturar dimensões diferentes do comportamento do mercado e, assim, permitir que macro e qualidade entrassem naturalmente respeitando o limite de 0,25.
6. Solução adotada e decisão final do conjunto de features
Após a análise de correlação pelo método de Pearson, ficou evidente que o conjunto inicial de variáveis era restrito e apresentava elevada sobreposição de informação. Essa redundância inviabilizava, simultaneamente, o cumprimento de um limite de correlação estatisticamente coerente e a manutenção de uma representatividade mínima por tópico econômico (tendência, volatilidade, stress, qualidade relativa e macro/sentimento). Em termos práticos, quando o filtro de correlação é mais rígido, variáveis construídas a partir de bases muito semelhantes passam a competir pelo mesmo sinal, o que reduz drasticamente o número de colunas elegíveis e, em alguns casos, elimina por completo tópicos considerados essenciais. A decisão foi guiada por três princípios:
1) Cobertura por tópico: ao menos uma variável por regime/tópico, preservando diversidade informacional; 2) Baixa redundância: manutenção do limite intermediário de ∣corr∣≤0,25, que equilibra viabilidade e controle de colinearidade; 3) Consistência temporal: cálculo das features em t usando apenas informações até t, pois o alvo do modelo é t+1.
6.1 Ampliação do universo de features como resposta ao problema de correlação
Para solucionar o problema de alta correlação entre as features, foram adicionadas ao projeto 27 features extras (arquivo features_extra.csv), com o objetivo de aumentar a diversidade de sinais disponíveis ao algoritmo de seleção e gerar alternativas menos colineares dentro de cada tópico (por exemplo, trocar “nível de volatilidade” por “instabilidade da volatilidade”, ou trocar “retorno acumulado” por “estrutura temporal do retorno”, como autocorrelação).
O princípio dessa ampliação foi incluir variáveis que capturam dimensões diferentes do comportamento do preço, em horizontes distintos (14d, 60d, 90d, 180d), reduzindo a probabilidade de colinearidade. Priorizou-se a inclusão de: indicadores de tendência alternativos e com janelas diferentes (momentum 14d/60d e cruzamento de médias), medidas de volatilidade com outra formulação (volatilidade de volatilidade, Parkinson e “realized vol” em janelas distintas), além de decomposições do fator macro/sentimento (FGI) que vão além do nível, incluindo variações, normalizações e persistência (variações do FGI em 1d/7d/14d, z-score 90d, volatilidade do FGI em 30d, posição relativa/rank em 180d e diferença para a média móvel/EMA). Esse aumento do universo foi consolidado no arquivo features_base_all.csv, que passou a conter o conjunto amplo (inicial + extras), servindo como base para a seleção final.
6.2 Procedimento de seleção final
Com o universo ampliado, a seleção foi executada com lógica por grupos (tópicos), impondo:
1) limite máximo de correlação absoluta ∣corr∣ ≤ 0,25 entre as features escolhidas; 2) Pelo menos uma feature por tópico; 3) Remoção preventiva de variáveis indesejadas (ret_1d), por serem tipicamente muito próximas do alvo ou elevarem a redundância sem agregar um “regime” adicional.
Operacionalmente, o filtro adotou a seguinte estratégia: para cada tópico, avaliou-se a lista de candidatos e escolheu-se a variável que minimizava conflito (correlação) com as já selecionadas. Quando o conjunto inicial falhava, o universo ampliado forneceu alternativas menos correlacionadas que permitiram completar todos os tópicos mantendo o limite.
6.3 Lista final de features selecionadas
Com o dataset final pronto, foi realizada correlação novamente, obtendo 5 features no total. Os coeficientes permanecem próximos de zero. Esse resultado é consistente com o objetivo do filtro: manter representatividade dos tópicos (tendência, volatilidade, stress, qualidade relativa e macro/sentimento) sem que diferentes colunas capturem o mesmo sinal. Na prática, a baixa correlação sugere que cada feature tende a adicionar informação marginal ao modelo, reduzindo risco de multicolinearidade. Por fim, a presença de correlações residuais pequenas e pontuais é esperada em séries financeiras, mas não compromete o critério de seleção adotado.
Figura 3 - Heatmap de Correlação do Conjunto Final de Features
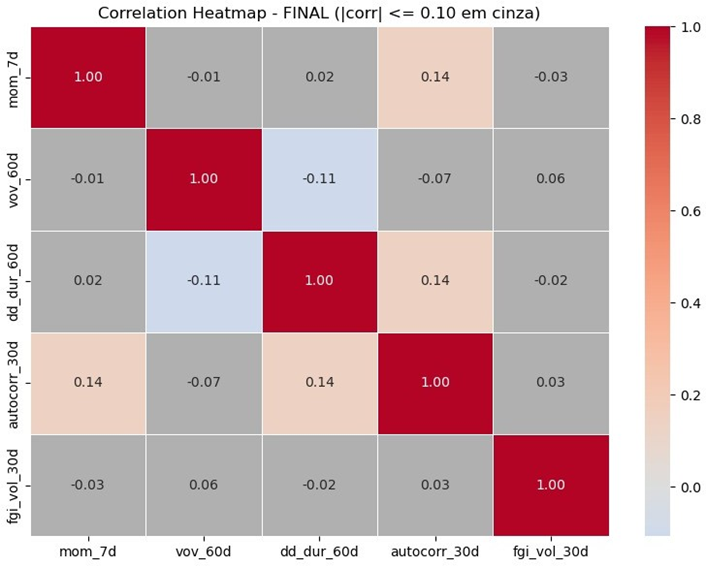
Info
Legenda: A escala de cores varia de -1 (azul) a +1 (vermelho). As células em cinza destacam pares com correlação muito baixa, isto é, próximo a 0.
Desse modo, ao final do processo, o dataset final/features_normal_datasetfinal.csv passou a conter uma feature representativa por tópico, com o seguinte conjunto:
- Tendência - mom_7d: Captura direção e intensidade recente do movimento de preço em janela curta, sensível a mudanças de regime e reversões de curto prazo. É simples, interpretável e funciona como proxy básica de “força” direcional.
- Volatilidade - vov_60d (volatility of volatility): Em vez de medir apenas “o nível de risco”, a métrica captura a instabilidade do risco (quando a volatilidade muda rápido). Em cripto, essa característica tende a diferenciar regimes com o mesmo nível médio de volatilidade, mas com comportamentos muito distintos (ex.: estabilização vs. transição para stress).
- Stress - dd_dur_60d (duração do drawdown): Complementa a volatilidade ao medir persistência de crise (tempo “debaixo d’água”), diferenciando quedas rápidas e recuperações rápidas de cenários de deterioração prolongada. Essa métrica agrega assimetria e memória de perdas, importantes em mercados com caudas pesadas.
- Qualidade relativa - autocorr_30d: Mede a estrutura temporal do retorno (dependência serial). Em termos práticos, ajuda a separar ativos/regimes com comportamento mais “tendencial” (autocorrelação positiva) daqueles mais “reversivos” ou ruidosos (autocorrelação negativa ou próxima de zero). Isso fornece uma dimensão adicional de qualidade do sinal que não é apenas retorno ou risco.
- Macro/Sentimento - fgi_vol_30d (volatilidade do Fear & Greed Index): Ao invés de usar somente o nível do índice, a variação/instabilidade do sentimento agregado tende a capturar mudanças do ambiente de risco (transições de humor), frequentemente associadas a reprecificações e regimes mais turbulentos.
6.4 Metodologia de cálculo das features selecionadas
- Pₜ: preço de fechamento no dia t;
- rₜ: retorno diário em t, tipicamente (ou retorno simples; o projeto manteve consistência interna, desde que a mesma definição seja usada em todas as features);
- todas as janelas são rolling e calculadas por ativo (Ticker), ordenadas por data;
- como o alvo do modelo é t+1, todas as features em t utilizam apenas informação até t (ou seja, sem olhar o futuro).
6.4.1 mom_7d (tendência de curto prazo)
Uma forma padrão e interpretável para momentum é o retorno acumulado em janela fixa:
Essa métrica resume a direção e magnitude do movimento recente, funcionando como proxy de tendência em curtíssimo prazo, usual em séries de alta volatilidade.
6.4.2 vov_60d (instabilidade da volatilidade)
A lógica é medir o quanto a volatilidade muda ao longo do tempo:
6.4.3 dd_dur_60d (duração do drawdown)
Primeiro define-se o pico recente (janela de 60 dias):
O drawdown corrente é:
“ A duração do drawdown pode ser definida como quantos dias o ativo está abaixo do último pico. Essa variável mede persistência de perda: quanto maior, mais “prolongada” a fase de recuperação/estresse.
6.4.4 autocorr_30d (qualidade estrutural do retorno)
Define-se a autocorrelação de primeira ordem em janela de 30 dias:
Valores positivos sugerem persistência (tendência/continuidade), valores negativos sugerem reversão e valores próximos de zero sugerem comportamento mais aleatório no curtíssimo prazo.
O objetivo não é prever diretamente a direção do preço pelo índice, mas capturar mudança de ambiente: quando o sentimento oscila muito, tende a indicar incerteza e transição de regime.
7. Fuzzificação das features
A fuzzificação foi empregada como uma etapa de transformação das features contínuas em representações baseadas em graus de pertinência (membership), com o objetivo de capturar a natureza inerentemente incerta e não linear do mercado de criptoativos. Em vez de tratar cada variável apenas como um valor numérico exato, a lógica fuzzy permite representar estados qualitativos do mercado (por exemplo, bear/neutral/bull, baixa/média/alta volatilidade, stress prolongado, sentimento instável) de forma gradual, isto é, com transições suaves entre categorias (por exemplo, um mercado pode estar “moderadamente estressado” em vez de simplesmente “estressado ou não”). Essa abordagem é particularmente relevante em cripto, pois a dinâmica de preço costuma apresentar mudanças de regime rápidas e grande sensibilidade a eventos externos, o que torna a interpretação puramente linear mais frágil em determinados contextos.
Além disso, a fuzzificação foi estruturada para permitir a comparação direta entre dois conjuntos: dataset com features contínuas e dataset com features fuzzyficadas, mantendo a mesma base temporal e os mesmos ativos, de forma que a diferença observada no desempenho do modelo seja atribuída à forma de representação do sinal (contínua vs. fuzzy). Na prática, essa transformação cria um conjunto de colunas adicionais, cada uma representando um rótulo fuzzy, que alimenta o modelo com uma leitura mais interpretável dos regimes. Como resultado, o dataset deixa de ter apenas poucas colunas numéricas e passa a ter múltiplas colunas de pertinência, em que valores próximos de 1 indicam forte aderência ao regime e valores próximos de 0 indicam baixa aderência.
7.1 Estrutura do dataset fuzzyficado
O arquivo final foi construído mantendo colunas de identificação e preço para alinhamento temporal e validação, seguidas pelas colunas de pertinência fuzzy. A estrutura final ficou com as seguintes colunas (com cada grupo de três colunas representa um único tópico econômico):
1) Colunas de base: date, ticker, close, 2) Tendência: trend_bear, trend_neutral, trend_bull, 3) Volatilidade: vol_low, vol_mid, vol_high, 4) Stress: stress_low, stress_mid, stress_high, 5) Qualidade Relativa: ac_negative, ac_neutral, ac_positive, 6) Macro/sentimento: macro_calm, macro_neutral, macro_stress.
Em termos de leitura, por exemplo, um valor alto em trend_bull indica que, naquele dia, a feature de tendência apontou forte aderência a um cenário de alta. Já um valor alto em stress_high indica maior aderência a um ambiente de stress.
7.2 Primeira tentativa e por que “um fuzzy igual para tudo” não funciona
A primeira tentativa adotou a mesma lógica de fuzzificação para todas as features, isto é, o mesmo tipo de função e a mesma forma de particionamento em “baixo / médio / alto” (ou equivalentes), independentemente do significado econômico e da distribuição estatística da variável. Nessa abordagem, o estado intermediário foi modelado como uma “zona estável” mais ampla, utilizando função trapezoidal, justamente para representar um intervalo de neutralidade em que pequenas variações do indicador não deveriam alterar significativamente a leitura do regime. Já os extremos foram representados por funções mais “pontudas” (como triangulares), de modo a captar transições mais claras para cenários de baixa ou alta intensidade. Essa abordagem é intuitiva no início, porém, ela se mostrou limitada porque forçou features com distribuições e dinâmicas distintas (por exemplo, tendência vs. stress) a seguirem o mesmo formato de pertinência, reduzindo a capacidade de cada variável expressar adequadamente o seu comportamento específico.
O principal motivo da limitação é que as features não vivem no mesmo mundo estatístico. Algumas são naturalmente limitadas (por exemplo, autocorrelação em −1,1), outras são estritamente positivas e com cauda longa (por exemplo, duração de drawdown), e outras variam em escalas diferentes e com ruído estrutural (por exemplo, métricas de volatilidade). Quando se impõe um mesmo molde fuzzy, os conjuntos acabam ficando mal calibrados, gerando pertinências pouco informativas, além de comprometer a interpretação econômica de cada regime.
Por fim, a fuzzificação uniforme aumenta a chance de gerar colunas fuzzy altamente semelhantes entre si (inclusive entre tópicos), pois a transformação deixa de refletir a natureza do sinal e passa a representar apenas uma discretização genérica. Assim, concluiu-se que a fuzzificação deveria ser tratada feature a feature, isto é, cada variável deveria receber um desenho de pertinência compatível com sua interpretação econômica e propriedades estatísticas.
7.3 Abordagem final: fuzzyficação por feature
A solução foi aplicar fuzzyficação por feature, respeitando o comportamento esperado de cada variável e o tipo de regime que ela pretende capturar, aplicando uma função de pertinência adequada para cada variável, respeitando três critérios:
1) Coerência econômica (o que significa “alto” ou “baixo” para aquela variável); 2) Comportamento estatístico (forma da distribuição e existência de zona central ou caudas relevantes); 3) Transição gradual (evitar classificações duras, permitindo sobreposição entre estados).
Em termos práticos, isso significa que cada feature passou a ter:
1) Funções de pertinência compatíveis com sua distribuição (triangular/trapezoidal/gaussiana); 2) Parâmetros calibrados por quantis, para evitar “chute” manual e manter robustez;
A calibração por quantis foi central para dar estabilidade ao processo. Em vez de escolher limites fixos, foram usados percentis da própria amostra (10%, 25%, 50%, 75%, 90%), definindo um grupo de percentis que fazia sentido para cada feature, o que permite que os cortes se ajustem à escala real dos dados e reduz sensibilidade a outliers. As funções utilizadas foram: triangular, trapezoidal e gaussiana, combinadas de acordo com a natureza da variável.
7.4 Racional das features fuzzyficadas
7.4.1 Tendência - triangular (mom_7d → trend_bear, trend_neutral, trend_bull)
A feature de momento em 7 dias foi convertida em três regimes: baixa, neutro e alta. A zona neutra foi construída como trapezoidal, propositalmente mais plana ao redor do centro, enquanto os extremos foram triangulares para captar transições mais claras. Foram calculados quantis: q10, q25, q40, q50, q60, q75, q90. Após conversão numérica, valores faltantes foram preenchidos por q50. As funções ficaram:
trend_bear: triangular(q10, q25, q50)trend_neutral: trapezoidal(q40, q50, q50, q60)trend_bull: triangular(q50, q75, q90)
Isso garante que “neutro” seja concentrado próximo da mediana, enquanto “bear” e “bull” ganham força conforme a variável se afasta do centro.
7.4.2 Volatilidade - gaussiana (vov_60d → vol_low, vol_mid, vol_high)
A variável vov_60d mede instabilidade da volatilidade, e portanto tende a apresentar concentração em um intervalo típico com caudas ocasionais associadas a mudanças abruptas de regime. Para esse tipo de variável, adotaram-se funções gaussianas para os estados (baixa, média, alta), pois a gaussiana representa bem situações em que existe um “valor típico” ao redor do qual a pertinência é maior, decaindo suavemente conforme o valor se afasta do centro. Essa forma é especialmente adequada para variáveis ruidosas e não lineares, pois evita fronteiras rígidas e reduz a sensibilidade excessiva a pequenas oscilações. Foram usados q25, q50 e q75 como centros das gaussianas. A dispersão foi definida de forma robusta usando o intervalo interquartil, com a aproximação do desvio-padrão para distribuições normais, com piso numérico mínimo para estabilidade:
As funções ficaram:
vol_low: gaussiana com e via IQRvol_mid: gaussiana com e via IQRvol_high: gaussiana com e via IQR
7.4.3 Stress - trapezoidal e triangular (dd_dur_60d → stress_low, stress_mid, stress_high)
A duração do drawdown (dd_dur_60d) mede persistência de crise. Aqui, o conceito econômico relevante é a existência de faixas. Como há uma região onde o estado pode ser considerado claramente ativo (por exemplo, stress prolongado após determinado número de dias), utilizar funções trapezoidais é adequado, pois elas permitem uma “zona plana” de pertinência igual a 1 em intervalos que representam regimes bem definidos, com rampas de transição antes e depois.
A duração do drawdown tem característica assimétrica e cauda longa. Para estabilizar a escala e reduzir a influência de valores extremos, foi aplicada transformação (com x ≥ 0):
Depois disso, foram calculados quantis q10, q25, q50, q75, q90 sobre z. A construção seguiu o mesmo racional de zona neutra mais estável:
● stress_low: triangular(q10, q25, q50) ● stress_mid: trapezoidal(q25, q50, q50, q75) ● stress_high: triangular(q50, q75, q90)
7.4.4 Qualidade Relativa - triangular (autocorr_30d → ac_negative, ac_neutral, ac_positive)
A autocorrelação (autocorr_30d) pode ser negativa, próxima de zero ou positiva. Em termos práticos, valores negativos sugerem comportamento reversivo, valores próximos de zero sugerem ausência de estrutura temporal clara, e valores positivos sugerem persistência . Assim, adotou-se fuzzificação em três estados com funções triangulares, pois há um centro interpretável, a transição entre “reversivo” e “persistente” deve ser contínua e o objetivo não é classificar de forma rígida, mas medir intensidade gradual de comportamento temporal.
Na prática, a autocorrelação é naturalmente limitada, então os valores foram truncados para o intervalo [-1, 1] antes da fuzzificação. O regime “neutro” foi definido como proximidade de zero, enquanto os regimes “negativo” e “positivo” refletem persistência direcional. A parametrização usou quantis q10, q40, q50, q60, q90 (com preenchimento de faltantes por q50). As funções ficaram:
● ac_negative: triangular(-1.0, q10, 0.0) ● ac_neutral: trapezoidal(q40, 0.0, 0.0, q60) ● ac_positive: triangular(0.0, q90, 1.0).
7.4.5 Macro/Sentimento - gaussiana e trapezoidal (fgi_vol_30d → macro_calm, macro_neutral, macro_stress)
A variável final do tópico macro selecionada foi fgi_vol_30d, que mede instabilidade do Fear & Greed Index. Diferentemente do nível do FGI (que tem faixa interpretativa conhecida), a volatilidade do FGI é uma métrica de “ambiente” e tende a ter uma região central interpretável (estabilidade típica) e caudas associadas a transições bruscas de sentimento. Por isso, foi adotada uma representação combinando: estados extremos com funções gaussianas (capturando picos de pertinência em níveis típicos de baixa ou alta instabilidade) e uma região central com trapezoidal
(representando a zona de estabilidade relativa com pertinência elevada em um intervalo). Essa escolha melhora a interpretação do macro como “ambiente estável vs. ambiente instável”, em vez de produzir apenas cortes genéricos.
Na prática, para o proxy macro/sentimento foi utilizada a volatilidade do índice de medo e ganância (FGI) como leitura de instabilidade do ambiente. A opção por gaussianas segue o racional de transição suave e ausência de cortes rígidos. A parametrização foi feita com três quantis q25, q50, q75 como centros e dispersão via IQR:
Resultando em:
● macro_calm: gaussiana com μ = q25 ● macro_neutral: gaussiana com μ = q50 ● macro_stress: gaussiana com μ = q75
7.5 Construção do dataset fuzzificado e padronização do pipeline
O dataset fuzzificado foi construído de forma padronizada, preservando o mesmo índice do dataset contínuo: (Date, Ticker). Para cada feature contínua, foram geradas múltiplas colunas fuzzy correspondentes aos termos linguísticos definidos (por exemplo, trend_bear, trend_neutro, trend_bull). O resultado é um dataset em que cada linha representa um ativo em um dia específico e cada coluna representa um grau de pertinência em [0,1].
O processo seguiu as seguintes etapas operacionais:
1) leitura do arquivo final de features contínuas selecionadas (features_normal_datasetfinal.csv); 2) verificação de colunas necessárias e ordenação por Ticker e Date; 3) aplicação das funções de pertinência específicas por variável; 4) montagem do output apenas com Date, Ticker e colunas fuzzy; 5) salvamento do arquivo final (features_fuzzy_datasetfinal.csv).
Esse pipeline garante rastreabilidade e repetibilidade, permitindo que o mesmo procedimento seja reexecutado sempre que o conjunto final de features for atualizado.
8. Modelagem supervisionada
8.1 Modelos avaliados e justificativa
A escolha do CatBoost em detrimento do XGBoost fundamenta-se em sua maior robustez em ambientes ruidosos e altamente voláteis, característica essencial no contexto do mercado de criptoativos. Embora o CatBoost permita o tratamento nativo de variáveis categóricas e o aprendizado conjunto de múltiplos ativos, neste projeto optou-se pela construção de 10 datasets separados, um para cada cripto ativo analisado, com o objetivo de preservar as dinâmicas individuais e os diferentes regimes de mercado associados a cada ativo. Em comparação ao XGBoost, o CatBoost é menos sensível a variações nos hiperparâmetros, reduzindo o risco de ajustes excessivos e mitigando o problema de overfitting, especialmente relevante em séries financeiras, onde o modelo pode facilmente memorizar padrões históricos sem capacidade de generalização. Essa propriedade torna-se ainda mais importante considerando que a variável de volatilidade utilizada no modelo é altamente sensível a mudanças abruptas e ruído de mercado. O CatBoost apresenta desempenho superior na modelagem de relações não lineares complexas, comuns em mercados financeiros e particularmente acentuadas no mercado de criptoativos. Mesmo operando sobre datasets individuais, o algoritmo mantém estabilidade e consistência na captura de padrões relevantes, sem demandar extensiva engenharia manual de atributos, o que favorece a escalabilidade e a reprodutibilidade do modelo.
8.2 Setup experimental (mesmo protocolo para clássico vs fuzzificado)
Após o processo de normalização e separação temporal dos dados, realizado em um script específico de pré-processamento, foram gerados 40 arquivos distintos, correspondentes às versões fuzzyficadas e não fuzzyficadas dos dados, já organizados em conjuntos de treino e teste para cada cripto ativo. A partir desses arquivos, foram considerados 20 datasets de treino independentes, os quais foram utilizados como entrada em um pipeline de treinamento e avaliação baseado no algoritmo CatBoost. Para cada cripto ativo, os modelos foram avaliados considerando diferentes horizontes de previsão (1, 7 e 30 dias), permitindo analisar o desempenho do Catboost em múltiplas escalas temporais. O pipeline implementado realiza a otimização de hiperparâmetros por meio da biblioteca Optuna, utilizando o método TPE (Tree-structured Parzen Estimator), com 50 trilhas por configuração.
8.3 Treino/validação temporal (walk-forward ou split fixo)
O processo de validação emprega Time Series Split, respeitando a ordenação temporal dos dados e incorporando um gap dinâmico proporcional ao horizonte de previsão, de modo a mitigar o risco de vazamento de informação entre os conjuntos de treino e validação. O modelo adotado foi configurado com ponderação automática de classes, visando lidar com possíveis desbalanceamentos na variável alvo. A função objetivo da otimização baseia-se no F1-score macro, com penalização da variância entre os folds, favorecendo configurações mais estáveis e robustas. Após a seleção dos melhores hiperparâmetros, cada modelo é treinado novamente sobre o conjunto completo de treino e avaliado em um conjunto de teste temporalmente separado, correspondente a 20% dos dados, previamente definidos no estágio de pré-processamento.
8.4 Hiperparâmetros e tuning (como foi feito, risco de overfit)
O ajuste dos hiperparâmetros foi realizado por meio de Otimização Bayesiana, utilizando o framework Optuna, com o objetivo de maximizar o F1-score macro, métrica escolhida por ser mais adequada a cenários com possíveis desbalanceamentos entre classes. O método de amostragem adotado foi o TPE (Tree-structured Parzen Estimator), conforme implementado pelo TPE Sampler.
O espaço de busca foi delimitado a fim de controlar a complexidade do modelo e reduzir o risco de overfitting. A profundidade das árvores (depth) foi limitada ao intervalo entre 3 e 8, restringindo modelos excessivamente complexos. A taxa de aprendizagem (learning_rate) foi amostrada em uma escala logarítmica, variando entre 0,005 e 0,1, permitindo explorar tanto regimes de aprendizado mais conservadores quanto mais rápidos. O parâmetro de regularização L2 (l2_leaf_reg), com valores variando entre 0,1 e 30, visando penalizar pesos excessivos nas folhas e aumentar a estabilidade do modelo. O parâmetro bagging temperature, responsável por controlar o grau de aleatoriedade na amostragem durante o treinamento, foi otimizado no intervalo entre 0 e 1, contribuindo para a redução da variância e mitigação de overfitting em dados ruidosos.
Durante a otimização, foi aplicado early stopping nos folds de validação, interrompendo o treinamento quando não havia melhora no desempenho por um número consecutivo de iterações. Essa estratégia previne que o modelo se ajuste excessivamente ao conjunto de treino. Após a seleção dos melhores hiperparâmetros, o modelo final foi treinado com 1000 iterações sobre o conjunto completo de treino.
8.5 Métricas de classificação (F1 macro, Log Loss, accuracy, matriz confusão)
O desempenho dos modelos foi avaliado por meio de métricas de classificação complementares, adequadas a um problema multiclasses de previsão de regimes de retorno. O F1-score macro foi adotado como principal indicador de desempenho, por sintetizar o equilíbrio entre precisão e revocação de forma uniforme entre as classes. A Acurácia foi utilizada como métrica auxiliar para fornecer uma visão global da taxa de acertos do modelo. O Log Loss foi empregado para avaliar a qualidade das probabilidades previstas, penalizando previsões incorretas associadas a altos níveis de confiança. Essa métrica permite analisar não apenas a classe prevista, mas também a coerência da distribuição probabilística gerada pelo modelo. As Matrizes de Confusão foram utilizadas como ferramenta interpretativa, possibilitando a identificação dos padrões de acerto e erro entre as classes de retorno. Essa análise permitiu avaliar a capacidade do modelo em diferenciar movimentos direcionais extremos das oscilações associadas à classe intermediária, contribuindo para uma interpretação mais detalhada do comportamento do classificador.
8.6 Resultados preditivos
8.6.1. F1-Score Macro
Os resultados preditivos foram avaliados individualmente por ativo e horizonte temporal, bem como de forma agregada, utilizando o F1-score macro como métrica de desempenho. A figura abaixo apresenta a comparação entre o modelo treinado com dados não-fuzzificados (Normal) e o modelo treinado com dados fuzzificados (Fuzzy).
Figura 4 Comparação de Desempenho Preditivo por Ativo e Horizonte Temporal (F1-score Macro): Normal vs. Fuzzy
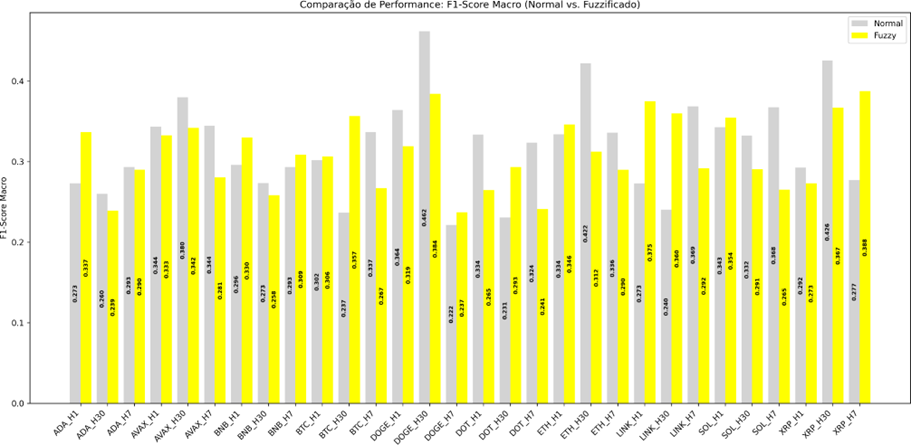
De forma desagregada por ativo, observa-se que o impacto da fuzzificação não é uniforme. Na análise desagregada por ativo e horizonte de previsão, observa-se um comportamento heterogêneo entre os modelos normal e fuzzificado. Para ADA, o modelo fuzzificado supera o normal em H1, enquanto o modelo normal apresenta melhor desempenho em H30 e H7. Em AVAX, o modelo normal é superior nos três horizontes (H1, H7 e H30). Para BNB, há vantagem do modelo fuzzificado em H1 e H7, com inversão em H30, onde o modelo normal se destaca. Em BTC, o modelo fuzzificado apresenta melhor desempenho em H1 e H30, enquanto o modelo normal supera o fuzzificado em H7. No caso de DOGE, o modelo normal é superior em H1 e H30, enquanto o fuzzificado apresenta vantagem em H7. Para DOT, o modelo fuzzificado mantém desempenho superior de forma consistente H30, porém o normal desempenha melhor no H1 e H7. Em ETH, o modelo fuzzificado supera o normal em H1, com vantagem do modelo normal em H7 e H30. Para LINK, o modelo fuzzificado apresenta melhor desempenho em H1 e H30, enquanto o modelo normal se destaca em H7. Em SOL, o modelo normal é superior em H30 e H7, com vantagem do fuzzificado apenas em H1. Por fim, em XRP, o modelo fuzzificado supera o normal em H7, enquanto o modelo normal apresenta melhor desempenho em H1 e H30, evidenciando que os ganhos da fuzzificação não são uniformes e dependem fortemente do ativo e do horizonte temporal analisado.
Esses resultados indicam que a fuzzificação não produz ganhos sistemáticos de desempenho médio, mas pode atuar de forma pontual, influenciando positivamente determinadas séries temporais e horizontes de previsão. Assim, o efeito da fuzzificação depende das características específicas do ativo e da dinâmica temporal considerada, não sendo possível afirmar uma superioridade global em termos de F1-score macro.
8.6.2 Acurácia
Considerando a métrica de acurácia, a comparação por ativo e horizonte revela novamente um comportamento não uniforme entre os modelos. A figura abaixo apresenta a comparação entre o modelo treinado com dados não-fuzzificados (Normal) e o modelo treinado com dados fuzzificados (Fuzzy).
Figura 4 - Teste de Acurácia
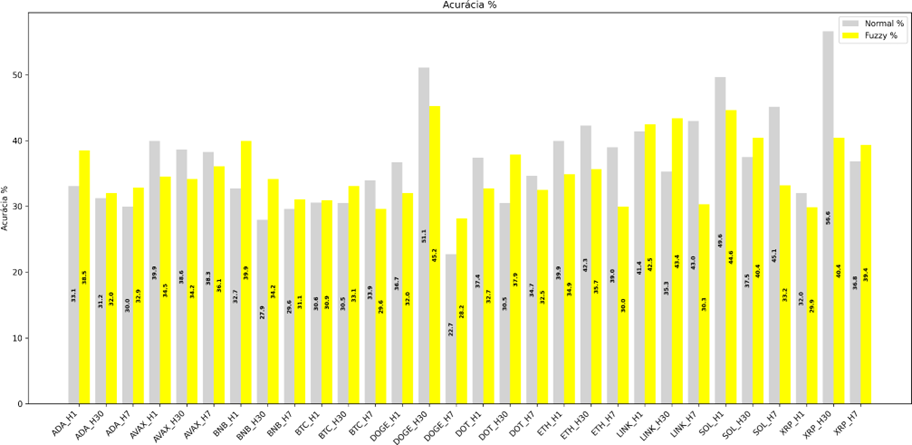
Para ADA, o modelo fuzzificado apresenta maior acurácia em H1 e H7, enquanto em H30 os desempenhos são muito próximos, com leve vantagem do fuzzificado. Em AVAX, o modelo normal supera o fuzzificado em H1, H7 e H30, indicando maior estabilidade sem fuzzificação. Para o BNB, observa-se vantagem do modelo fuzzificado em H1, H7 e H30. No caso do BTC, o modelo fuzzificado obtém melhores resultados em H1 e H30, enquanto em H7 a acurácia do modelo normal é ligeiramente maior. Para DOGE, o modelo normal apresenta acurácia significativamente superior em H30, enquanto o fuzzificado supera o normal em H7, e em H1 os resultados também indicam uma vitória do normal. Em DOT, o modelo fuzzificado apresenta maior acurácia em H30, o neutro é vitorioso no H1 e H7. Para ETH, o modelo normal é superior em H1, H7 e H30, mostrando que ele é mais eficaz para este ativo ao observar a acurácia. Em LINK, o modelo fuzzificado supera o normal em H1, H30, porém no H7 o modelo normal possui maior acurácia. Para SOL, o modelo normal apresenta maior acurácia em H1 e H7, enquanto o fuzzificado supera em H30. Por fim, em XRP, o modelo normal é superior em H1 e H30, ao passo que o modelo fuzzificado apresenta maior acurácia em H7, reforçando que os efeitos da fuzzificação variam substancialmente conforme o ativo e o horizonte temporal analisado.
De forma geral, a análise baseada na acurácia evidencia que a fuzzificação não introduz ganhos consistentes e generalizáveis ao longo de todos os ativos e horizontes de previsão. Seus benefícios manifestam-se de maneira pontual, com desempenho superior em determinados ativos e janelas temporais específicas, enquanto em outros contextos o modelo treinado com dados não fuzzificados mantém maior estabilidade e capacidade preditiva. Esses achados reforçam que o impacto da fuzzificação é fortemente dependente da estrutura temporal e do comportamento particular de cada ativo, não sendo possível caracterizá-la como uma melhoria universal do modelo, mas sim como um mecanismo potencialmente útil em cenários específicos.
8.6.3 Log Loss
Considerando o Log Loss como métrica de avaliação, que penaliza previsões probabilísticas mal calibradas, a comparação entre os modelos normal e fuzzificado evidencia diferenças relevantes na consistência das probabilidades estimadas ao longo dos ativos e horizontes de previsão. Valores menores de Log Loss indicam melhor calibração e maior confiança probabilística do modelo.
Figura 5 - Teste Log Loss
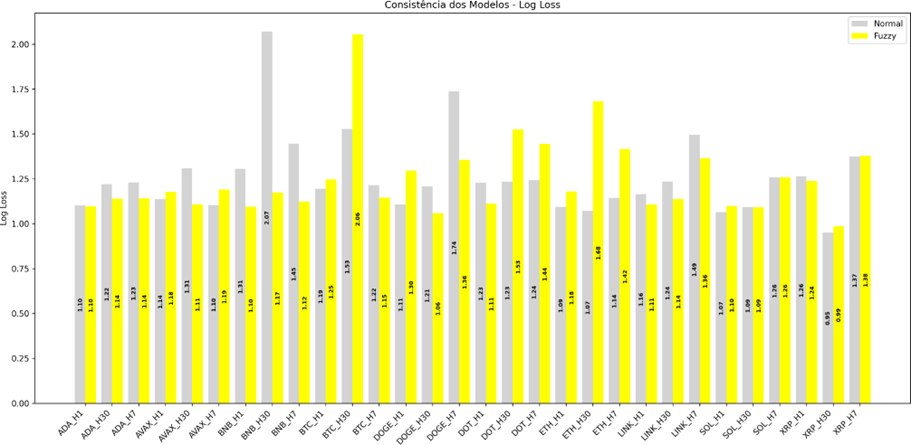
Para ADA, os resultados de Log Loss são praticamente equivalentes em H1, e o modelo fuzzy apresenta melhor desempenho em H7 e H30. Em AVAX, o modelo normal apresenta menor Log Loss em H1 e H7, enquanto o fuzzificado obtém melhor resultado em H30. Para BNB, o modelo fuzzificado supera o normal de forma clara em H30, e em H1 e H7 o modelo fuzzy apresenta Log Loss inferior. No caso do BTC, o modelo normal apresenta melhor calibração em H7, enquanto em H30 e H1 o modelo normal se mostra melhor com um Log Loss menor. Para DOGE, o modelo fuzzificado apresenta vantagem consistente em H7 e H30, enquanto em H1 o modelo normal apresenta melhor desempenho. Em DOT, o modelo fuzzificado apresenta Log Loss inferior em H1, enquanto em H7 e H30 o modelo normal se mostra mais consistente. Para ETH, o modelo normal apresenta menor Log Loss em H1, H7 e H30. Em LINK, observa-se vantagem do modelo fuzzificado em H1, H7 e H30. Para SOL, os resultados são próximos em H1, com pequena vantagem do modelo normal, e desempenho parecido em H7 e H30. Para XRP, o modelo fuzzy apresenta Log Loss inferior em H1, e o normal menor Log Loss em H30, e em H7 os desempenhos são bastante próximos.
8.6.4 Matriz de Confusão
-
ADA: No H1, vemos um viés forte do modelo normal de previsão da classe 2, que também ocorre no treino em H30 e no modelo fuzzy de H7. Destaque que não tivemos acerto das previsões de classe 0 do modelo fuzzy de H30. O modelo fuzzy apresenta mais acertos, em geral, que o normal.
-
AVAX: Matriz de confusão nos permite verificar o viés de previsão da classe 1 em H1 e H7, que não ocorre em H30. No modelo normal de H7, verificamos acerto de previsão de todas as classes 0, e no modelo fuzzy de H30, não há previsão 1 de casos em que a realidade era de classe 2. Para a AVAX o modelo normal tem mais acertos que o fuzzy nos três horizontes, em especial no H1, mas a diferença é pequena.
-
BNB: O modelo fuzzy nos três horizontes apresenta viés de previsão da classe 2, enquanto o normal também apresenta viés, mas para ambas as classes 0 e 2, com destaque à 2. Em H1 e H30 o modelo fuzzy apresentou apenas 7 e 2 acertos da classe 0, respectivamente. O modelo fuzzy apresenta maior quantidade de acertos, especialmente em H1 e H7.
-
BTC: Em todos os horizontes ambos os modelos apresentaram viés pela classe 0, que é menor em H7, mas ainda sim predomina sobre as demais classes. Destaque para os acertos particularmente baixos do modelo normal de H30 e do fuzzy de H7 da classe 2 (5 e 7, respectivamente). Acertos similares entre os dois modelos.
-
DOGE: Notamos a tendência no H7 do modelo fuzzy e no H30 do normal de prever classe 2. Em H30, o modelo fuzzy acerta 6 das 7 previsões de classe 0, enquanto o normal desse período se encontra mais distribuído entre as classes e em geral mais preciso. Modelo normal mais preciso em H1 e H30, mas perde em acertos para o fuzzy em H7.
-
DOT: É possível notar tendência de previsão de ambos os modelos nos três horizontes, na classe 2 em H1 e H7, e na classe 0 em H30. Destaque aos poucos acertos do fuzzy nos três horizontes do modelo fuzzy da previsão de classe 1 (5,2,1, respectivamente) e aos apenas 4 acertos de previsão 2 do modelo normal em H30. O modelo normal tende menos aos extremos em H1 e H7, exceto em H30, onde o oposto ocorre.
-
ETH: Em H1 e H7, o modelo normal tende à classe 1, e em H30 oscila principalmente entre 0 e 1. Para o fuzzy, a sua distribuição de previsões é mais concentrada em 2 em H7 e 0 em H30. Mais acertos no modelo normal que o fuzzy em H7 e H30, com previsões mais distribuídas entre as três classes no primeiro.
-
LINK: O modelo fuzzy apresenta viés de escolha em H1 e H30 pela classe 1, que também vemos nos três horizontes do modelo normal. Destaque para a previsão de classe 2 do modelo normal em H30, que teve apenas 2 acertos. Os modelos alternam em qual tem mais acertos por horizonte, mas concentração de previsões 1 do modelo normal que contribuem para mais acertos em períodos de 1, e menos em períodos de menos resultados reais de classe 1.
-
SOL: Os dois modelos no H1 tendem à classe 1. O fuzzy em H7 tende a 2 e em H30 a 1, e nos horizontes 7 e 30 acerta apenas 1 das suas previsões de classe 0. O modelo normal tende a acertar mais, exceto no H30, em que ambos têm números de acertos similares.
-
XRP: O modelo normal em H7 e H30 tem uma tendência a prever a classe 1. Comparado ao modelo normal, o fuzzy distribui mais as suas previsões entre as três classes, mas tem menos acertos em H1 e H30 que o normal.
Figura 6 - Matriz Modelo Fuzzy
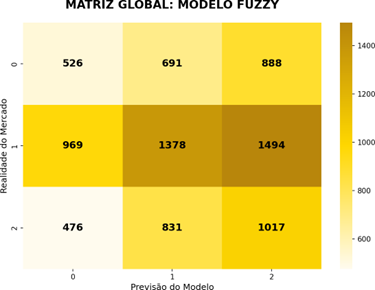
Figura 7 - Matriz Modelo Normal
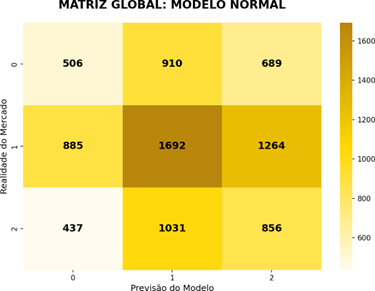
As matrizes globais consolidam os padrões observados nos dez criptoativos e revelam distinções fundamentais nas duas abordagens. A Matriz Global do Modelo Normal evidencia expressiva quantidade de previsões na Classe 1 (Neutro), totalizando 1.692 acertos nesta categoria. Esse fenômeno demonstra que o modelo busca mitigar o erro ao se refugiar na média do mercado, o que resulta em uma maior estabilidade teórica, mas compromete a captura de movimentos direcionais. Nota-se que, ao tentar prever a Classe 0 (Baixa), o modelo normal erra mais vezes ao classificar o movimento como neutro, 910 casos, do que acertando a baixa propriamente dita, 506 acertos.
Em contrapartida, a Matriz Global do Modelo Fuzzy revela um comportamento mais propenso a capturar tendências, embora carregue vieses mais acentuados. O modelo fuzzy obteve um desempenho superior na detecção da Classe 2 (Alta), com 1.017 acertos contra os 856 do modelo normal. Porém esse comportamento gera um erro de “otimismo” perigoso: quando a realidade do mercado era de queda (Classe 0), o modelo fuzzy previu alta (Classe 2) em 888 ocasiões, um número significativamente superior aos 526 acertos reais daquela classe. Esse dado corrobora a análise de que a fuzzificação, ao potencializar a detecção de sinais direcionais, pode induzir o CatBoost a ignorar sinais de baixa em prol de uma tendência de alta dominante.
Ao compararmos as duas distribuições, fica claro que o erro do Modelo Normal é um erro de omissão, ele falha em agir, preferindo a neutralidade, enquanto o erro do Modelo Fuzzy é um erro de comissão, ele age na direção errada ao se deixar levar por vieses de tendência. No modelo normal, a soma dos acertos nas classes extremas (0 e 2) é de 1.362, enquanto no modelo fuzzy esse valor sobe para 1.543. Entretanto, a matriz fuzzy mostra uma distribuição de erros mais espalhada para a direita, indicando que a sua maior taxa de acerto bruto vem acompanhada de uma maior exposição a riscos de inversão de mercado.
9. Explicabilidade e interpretação
9.1 SHAP Global com estabilidade temporal
A análise SHAP empregada neste trabalho é de natureza local e temporal, sendo aplicada diretamente sobre observações individuais do conjunto de teste. Para cada ativo e horizonte, são selecionadas as últimas N observações temporais, ordenadas do instante mais recente (T-0) ao mais distante no passado (T-9). Os valores são calculados a partir do método do CatBoost para modelos baseados em árvores, o qual utiliza uma decomposição aditiva da predição em contribuições marginais das variáveis. O valor de referência é implicitamente determinado pela estrutura do modelo e pela distribuição aprendida durante o treinamento.
Esta análise examina a evolução temporal da importância das variáveis em dois modelos distintos, um com representação fuzzy e outro com representação não- fuzzy (que foi apelidada de normal) utilizando valores SHAP médios globais. A abordagem temporal permite identificar não apenas quais variáveis são mais influentes, mas também quando sua influência é máxima ao longo do horizonte de previsão.
Figura 8 - Mapa Temporal de Importância SHAP (Média Global) por Janela Passada: Modelo Fuzzy vs. Normal
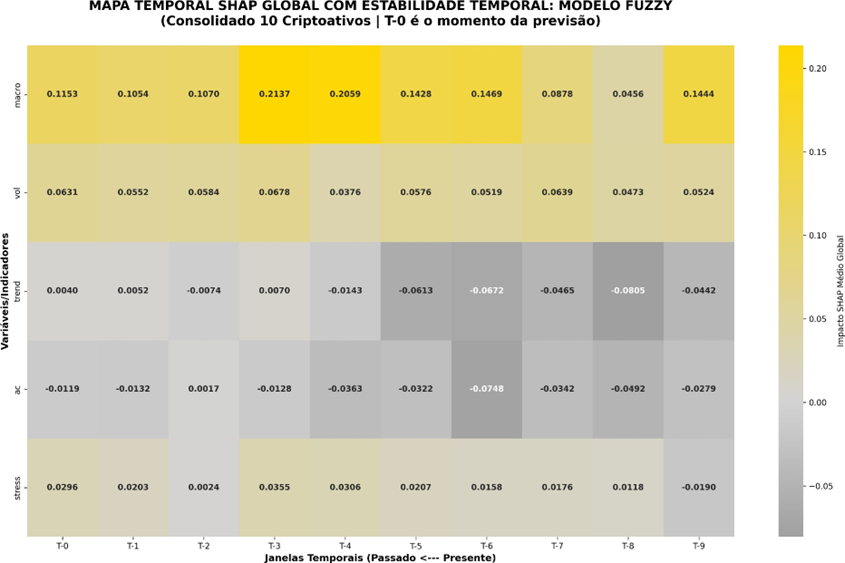
No modelo fuzzy, observa-se uma clara hierarquia de importância entre as variáveis analisadas. A variável macro (indicadores macroeconômicos) demonstra dominância absoluta em termos de magnitude de influência positiva, apresentando seu pico de contribuição no terceiro período antecedente. Esta variável mantém níveis elevados de importância nos períodos vizinhos ao seu pico, estabelecendo uma janela de influência crítica. A segunda variável em importância, vol (volatilidade), apresenta comportamento notavelmente estável ao longo de todo o horizonte temporal, com leve aumento de contribuição no mesmo período em que a variável principal atinge seu máximo. Esta consistência sugere um papel de suporte estrutural ao modelo, menos sensível a variações temporais específicas.
A variável ac (autocorrelação) que exerce influência negativa consistente. Esta atinge seu ponto de máxima influência negativa no sexto período antecedente, estabelecendo-se como o principal fator de redução nas previsões do modelo. A natureza uniformemente negativa de sua contribuição em todos os períodos sugere que atua como um mecanismo regulador ou contrapeso. A variável stress (estresse financeiro) apresenta comportamento mais ambíguo, com influência predominantemente positiva mas de impacto reduzido. Curiosamente, esta variável inverte seu sinal no período mais distante da previsão, indicando uma possível mudança na interpretação de seu sinal dependendo da janela temporal considerada.
Figura 8 - Mapa Temporal SHAP Global com Estabilidade Temporal: Modelo Normal (Consolidado 10 Criptoativos | T-0 é o momento da previsão)
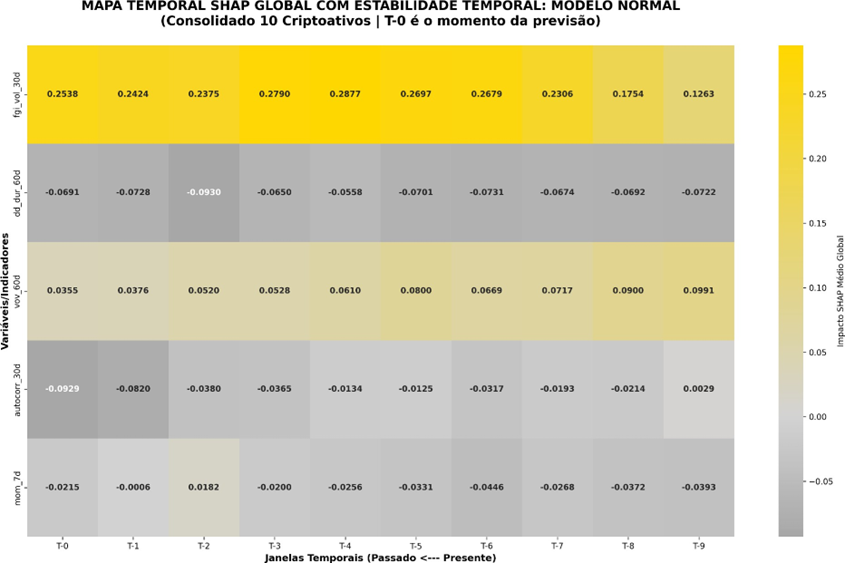
A característica mais marcante deste modelo é a hegemonia da variável fgi_vol_30d (volatilidade de 30 dias), ela apresenta um impacto positivo consistente em todas as janelas temporais.O ponto de maior influência ocorre especificamente entre os períodos T-3 (0.2790) e T-4 (0.2877), o que revela uma “memória de médio prazo”: o modelo dá mais peso ao comportamento da volatilidade de alguns dias atrás do que ao que está acontecendo no exato momento da previsão (T-0). Em contrapartida, o modelo utiliza a variável dd_dur_60d que funciona como um redutor constante de valor, mantendo um impacto negativo muito estável ao redor de -0.07. Outro comportamento interessante é observado na autocorr_30d.
Diferente da duração da queda, que é estável, a autocorrelação é altamente reativa ao presente. Seu impacto negativo é mais severo em T-0 (-0.0929) e vai se dissipando ao voltar no tempo, tornando-se praticamente irrelevante em T-9. Isso indica que o modelo enxerga a autocorrelação recente como um sinal de alerta imediato, possivelmente interpretando-a como um indício de saturação ou exaustão do movimento atual. Enquanto variáveis como vov_60d e mom 7d (momentum) oferecem apenas ajustes marginais e sutis, o núcleo da decisão reside na interação entre a força da volatilidade acumulada e os freios impostos pelos indicadores de risco e autocorrelação.
A combinação entre sinais persistentes, como a volatilidade, e freios estáveis, como o drawdown em 60 dias, sugere um comportamento conservador, pouco sensível a flutuações instantâneas, e orientado à filtragem de contextos em que o risco já se encontra excessivamente precificado.
9.2 SHAP Local com dimensão temporal
Foi realizada uma análise SHAP local com dimensão temporal consiste na avaliação das contribuições individuais das variáveis para uma previsão específica, considerando explicitamente suas janelas temporais, permitindo identificar não apenas quais atributos influenciam o modelo, mas também em quais momentos passados essa influência é mais relevante. São registradas a seguir as movimentações na importância de cada variável para a composição do SHAP, As vaariáveis estão ordenadas por ordem de importância em T4.
-
ADA:
- Normal (H1): A variável
autocorrcresce de T1 a T4, especialmente de T3 a T4. A variáveldd_duraumenta de T1 a T2, e diminui de importância até T4. A variávelvolaumenta de T1 a T3 e diminui entre T3 e T4. A variávelfgi_vol_30dvai aumentando entre T1 e T2, diminui entre T2 e T3, e aumenta novamente até T4. A variávelmomdiminui entre T1 e T2, e aumenta de T2 a T4. - Normal (H7): A variável
fgi_vol_30ddiminui relativamente entre T1 e T2, e aumenta de T2 a T4. A variáveldd_duraumenta de T1 a T3 e diminui de T3 a T4. A variávelautocorraumenta de T1 a T3, diminui de T3 a T4. A variávelmomdiminui entre T1 e T2 e aumenta de T2 a T4. A variávelvoldiminui de T1 a T4. - Normal (H30): A variável
dd_durdiminui de T1 a T2, aumenta de T2 a T3, e diminui de T3 a T4. A variávelautocorrsegue estável de T1 a T2, aumenta de T2 a T3, e diminui de T3 a T4. A variávelvolaumenta de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. A variávelmomsegue estável em importância de T1 a T2, diminui entre T2 e T3, e aumenta de T3 a T4. - Fuzzy (H1): A variável
stressaumenta de T1 a T2, segue estável entre T2 e T3, e aumenta novamente de T3 a T4. A variávelmacrodiminui de T1 a T4, diminuindo pouco entre T3 e T4 (comparada às demais e janelas anteriores). A variávelacdiminui pouco de T1 a T4, em comparação às oscilações de outras variáveis nessa janela. A variávelvolaumenta de T1 a T4. A variáveltrendaumenta de T1 a T4. - Fuzzy (H7): A variável
stressaumenta em importância de T1 a T3, e segue estável de T3 a T4. A variávelacdiminui relativamente pouco (comparada às demais) de T1 a T3, e aumenta de T3 a T4. A variávelmacrodiminui de T1 a T2, e aumenta de T2 a T4. A variávelvolaumenta de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. A variáveltrendsegue estável de T1 a T2 e aumenta de T2 a T4. - Fuzzy (H30): A variável mais importante em T4 é
stress, que aumenta de T1 a T2, e diminui pouco de T2 a T4 (em comparação às demais). A variávelmacrodiminui muito de T1 a T2 (em comparação a outras variáveis e ela mesma nas outras janelas), e aumenta de T2 a T4. A variávelvolaumenta de T1 a T2 e diminui de T2 a T4. A variávelacdiminui de T1 a T2 e aumenta de T2 a T4. A variáveltrendsegue estável ao longo de todas as janelas.
- Normal (H1): A variável
-
AVAX:
- Normal (H1): A variável
dd_dursegue estável de T1 a T2, aumenta de T2 a T3, e aumenta pouco (comparada às demais variáveis em outras janelas) de T3 a T4. A variávelfgi_voldiminui de T1 a T2, segue estável de T2 a T3, e aumenta de T3 a T4. A variávelvolsegue estável de T1 a T2, aumenta de T2 a T3, e novamente segue estável de T3 a T4. A variávelmomaumenta de T1 a T4, em comparação às demais. A variávelautocorraumenta de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. - Normal (H7): A variável
fgi_voldiminui de T1 a T2, e aumenta de T2 a T4. A variáveldd_durdiminui de T1 a T2, aumenta de T2 a T3, e diminui pouco de T3 a T4, comparada às demais. A variávelvoldiminui de T1 a T2, aumenta de T2 a T3, e diminui de T3 a T4. A variávelautocorrdiminui de T1 a T2, segue estável de T2 a T3, e aumenta de T3 a T4. A variávelmomaumenta de T1 a T2, segue estável de T2 a T3, e aumenta de T3 a T4. - Normal (H30): A variável
dd_duraumenta de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. A variávelfgi_voldiminui de T1 a T3, e aumenta de T3 a T4. A variávelvolsegue em aumento de T1 a T3, e diminui de T3 a T4. A variávelautocorrdiminui de T1 a T3, e aumenta de T3 a T4. A variávelmomdiminui de T1 a T2, e aumenta de T2 a T4. - Fuzzy (H1): A variável
trenddiminui de T1 a T3, e aumenta muito de T3 a T4, comparada às demais. A variávelmacrodiminui de T1 a T2, aumenta de T2 a T3, e segue estável de T3 a T4. A variávelacaumenta de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. A variávelvoldiminui de T1 a T2, aumenta de T2 a T3, e diminui de T3 a T4. A variávelstressaumenta de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. - Fuzzy (H7): A variável
volaumenta de T1 a T3 e diminui em T4. A variávelmacrodiminui muito de T1 a T2, segue estável de T2 a T3, e fica estável no período de T3 a T4. A variáveltrendaumenta de T1 a T4. A variávelacdiminui de T1 a T3 e fica estável entre T3 e T4. A variávelstressaumenta de T1 a T2, segue estável de T2 a T3, e diminui pouco de T3 a T4, comparada às flutuações anteriores. - Fuzzy (H30): A variável
stressdiminui de T1 a T2, aumenta de T2 a T3, e diminui de T3 a T4. A variávelvolaumenta de T1 a T2, segue estável de T2 a T4. A variávelmacroaumenta de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. A variávelacdiminui de T1 a T4. A variáveltrendsegue estável de T1 a T4.
- Normal (H1): A variável
-
BNB:
- Normal (H1): A variável
fgi_volaumenta de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. A variávelmomdiminui pouco de T1 a T2, comparada às demais, aumenta de T2 a T3, e diminui de T3 a T4. A variávelautocorrdiminui de T1 a T2, aumenta de T2 a T3, e diminui muito de T3 a T4, comparada às demais nessa janela. A variáveldd_duraumenta de T1 a T3 e diminui de T3 a T4. A variávelvoldiminui de T1 a T2, aumenta de T2 a T3, e diminui de T3 a T4. - Normal (H7): A variável
momdiminui de T1 a T2, aumenta de T2 a T3, e diminui de T3 a T4. A variávelautocorroscila muito, comparada às demais, com diminuição de T1 a T2, aumento de importância de T2 a T3, e diminuição de T3 a T4. A variávelvoltambém oscila muito, diminuindo de T1 a T2, aumento de T2 a T3, e diminui de T3 a T4. A variáveldd_duraumenta de T1 a T3 e diminui de T3 a T4. A variávelfgi_volaumenta de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. - Normal (H30): A variável
autocorrsegue estável de T1 a T2, aumenta de T2 a T3, e diminui de T3 a T4. A variáveldd_duraumenta de T1 a T3 e diminui de T3 a T4. A variávelvolé a que mais varia em importância entre elas, aumentando muito de T1 a T2, diminuindo muito de T2 a T3, e aumenta muito de T3 a T4. A variávelfgi_voldiminui de T1 a T4. A variávelmomsegue estável de T1 a T2, e aumenta de T2 a T4. - Fuzzy (H1): A variável
macroaumenta de T1 a T2 e aumenta de T3 a T4. A variávelstressaumenta de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. A variávelacdiminui de T1 a T2, aumenta de T2 a T3, e diminui muito de T3 a T4, comparada às demais. A variávelvolaumenta de T1 a T2, diminui muito de T2 a T3, e aumenta de T3 a T4. A variáveltrenddiminui de T1 a T2, aumenta de T2 a T3, e diminui de T3 a T4. - Fuzzy (H7): A variável
stressdiminui de T1 a T2 e aumenta de T2 a T4. A variávelvolaumenta muito de T1 a T2, diminui muito de T2 a T3, e ainda diminui, mas menos que antes, de T3 a T4. A variávelmacrosegue estável de T1 a T4. A variáveltrenddiminui de T1 a T2, aumenta de T2 a T3, e diminui de T3 a T4. A variávelacaumenta de T1 a T3, e diminui de T3 a T4. - Fuzzy (H30): A variável
stressdiminui de T1 a T2, aumenta de T2 a T3, e diminui de T3 e T4. A variávelmacrosegue estável de T1 a T4. A variávelmacroaumenta de T1 a T2, e segue estável de T3 a T4. A variávelvolaumenta muito de T1 a T2, comparada às demais, diminui de T2 a T3, e aumenta de T3 a T4. A variáveltrenddiminui de T1 a T2 e aumenta de T2 a T4.
- Normal (H1): A variável
-
BTC:
- Normal (H1): A variável
dd_duraumenta de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. A variávelvoldiminui de T1 a T2 e aumenta de T2 a T4. A variávelmomtambém diminui de T1 a T2 e aumenta de T2 a T4, mas a diminuição e subsequente aumento de importância são menores que os devol. A variávelautocorrdiminui de T1 a T2, aumenta de T2 a T3, e diminui de T3 a T4. A variávelfgi_voldiminui muito de T1 a T2, comparada às demais, segue diminuindo de T2 a T3, e aumenta de T3 a T4. - Normal (H7): A variável
dd_duraumenta de T1 a T2, aumenta muito de T2 a T3, e diminui de T3 a T4. A variávelautocorrdiminui de T1 a T2, comparada às demais, aumenta de T2 a T3, e diminui de T3 a T4. A variávelmomaumenta de T1 a T2, aumenta de T2 a T3, e diminui de T3 a T4. A variávelvolaumenta de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. A variávelfgi_volaumenta muito de T1 a T2, diminui muito de T2 a T3, e aumenta de T3 a T4. A variávelautocorredd_duraumentam muito de T2 a T3, comparadas às demais. - Normal (H30): A variável
dd_durdiminui de T1 a T2, aumenta muito de T2 a T3, e diminui muito de T3 a T4, quando comparada às demais nessas janelas. A variávelvolaumenta de T1 a T3 e diminui de T3 a T4. A variávelfgi_voldiminui de T1 a T3 e aumenta de T3 a T4. A variávelautocorrdiminui de T1 a T2, aumenta de T2 a T3, e diminui de T3 a T4. A variávelmomaumenta pouco de T1 a T2, diminui pouco de T2 a T3, e aumenta pouco de T3 a T4, comparada às demais nessas janelas. - Fuzzy (H1): A variável
macrodiminui de T1 a T2, aumenta de T2 a T3, e segue estável de T3 a T4. A variávelstressaumenta muito de T1 a T2, comparada às demais nessa janela, diminui muito de T2 a T3, e segue diminuindo, mas com valores menores de importância, de T3 a T4. A variáveltrendaumenta de T1 a T3 e diminui de T3 a T4. A variávelvoldiminui de T1 a T4, principalmente de T3 a T4. A variávelacdiminui de T1 a T2, aumenta de T2 a T3, e diminui muito de T3 a T4, tendo em vista a flutuação de importância de todas as variáveis nessa janela. - Fuzzy (H7): A variável
acdiminui de T1 a T2, aumenta de T2 a T3, e diminui de T3 a T4. A variávelstressaumenta de T1 a T3 e diminui de T3 a T4. A variávelmacroaumenta muito de T1 a T2, diminui muito de T2 a T3, e aumenta de T3 a T4. A variáveltrenddiminui de T1 a T2, aumenta de T2 a T3, e aumenta de T3 a T4. A variávelvolaumenta de T1 a T3 e diminui de T3 a T4. - Fuzzy (H30): A variável
stressaumenta de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. A variávelmacroaumenta muito de T1 a T2, diminui de T2 a T4, e segue aumentando de T3 a T4. A variáveltrendtem flutuação de importância pequena quando comparada às demais variáveis, diminui de T1 a T2, aumenta de T2 a T3, e segue estável de T3 a T4. A variávelacdiminui muito de T1 a T2, na comparação às demais entre T1 e T2, aumenta de T2 a T3, e segue estável de T3 a T4.
- Normal (H1): A variável
-
DOGE:
- Normal (H1): A variável
momaumenta de T1 a T3 e diminui de T3 a T4. A variávelfgi_volsegue estável de T1 a T2, diminui muito de T2 a T3 (comparada às demais) e aumenta muito de T3 a T4. A variávelvolaumenta de T1 a T2, diminui pouco de T2 a T3, e aumenta pouco de T3 a T4. A variáveldd_durdiminui de T1 a T3, com destaque de T2 a T3, e aumenta de T3 a T4. A variávelautocorrdiminui de T1 a T2 e aumenta de T2 a T4. - Normal (H7): A variável
momaumenta de T1 a T2 e diminui de T2 a T4. A variáveldd_durdiminui muito de T1 a T2, aumenta de T2 a T3, e diminui de T3 a T4. A variávelfgi_voldiminui de T1 a T2, segue estável de T2 a T3, e aumenta de T3 a T4. A variávelvolaumenta de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. A variávelautocorraumenta muito de T1 a T2, comparada às demais, segue estável de T2 a T3, e diminui de T3 a T4. - Normal (H30): A variável
volaumenta de T1 a T2, diminui pouco (comparada às demais) de T2 a T3, e aumenta de T3 a T4. A variávelfgi_voldiminui muito de T1 a T2 (comparada às demais), diminui de T2 a T3, e aumenta de T3 a T4. A variáveldd_duraumenta de T1 a T3 e diminui de T3 a T4. A variávelautocorraumenta de T1 a T2 e segue estável de T2 a T4. A variávelmomaumenta de T1 a T2 e diminui de T2 a T4. - Fuzzy (H1): A variável
macrodiminui de T1 a T3, especialmente entre T2 e T3, onde sua importância diminui de forma mais acentuada, e aumenta de T3 a T4. A variáveltrendaumenta de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. A variávelstressdiminui de T1 a T2, aumenta de T2 a T3, e diminui de T3 a T4. A variávelvoldiminui de T1 a T2, aumenta de T2 a T3, e diminui de T3 a T4, comparada às demais nessa janela. A variávelacaumenta muito de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. - Fuzzy (H7): A variável
acaumenta muito de T1 a T2, comparada às demais em todas as janelas, diminui de T2 a T3, e aumenta de T3 a T4. A variávelvoldiminui de T1 a T2, aumenta de T2 a T3, e diminui de T3 a T4. A variávelmacrodiminui muito de T1 a T2, aumenta muito de T2 a T3, e diminui de T3 a T4. A variávelstressaumenta de T1 a T3 e diminui de T3 a T4. A variáveltrenddiminui de T1 a T2 e aumenta de T2 a T4. - Fuzzy (H30): A variável
acaumenta de T1 a T3 e diminui de T3 a T4. A variávelvolaumenta de T1 a T4. A variávelmacrodiminui de T1 a T3 e aumenta de T3 a T4. A variávelstressaumenta de T1 a T3 e diminui de T3 a T4. A variáveltrendsegue …
- Normal (H1): A variável
-
DOT:
- Normal (H1): A variável
autocorraumenta de T1 a T2, diminui de T2 a T3, e aumenta muito de T3 a T4, comparada às demais nessa janela. A variávelmomaumenta muito de T1 a T2 (comparada às demais) e diminui de T2 a T4. A variávelfgi_voldiminui muito de T1 a T2 (comparada às demais) e aumenta de T2 a T4. A variávelvolaumenta de T1 a T2 e diminui de T2 a T4. A variáveldd_duraumenta de T1 a T3 e aumenta muito de T3 a T4. - Normal (H7): A variável
autocorraumenta de T1 a T3 e aumenta muito de T3 a T4, em relação às outras variáveis. A variáveldd_duraumenta de T1 a T2 e diminui pouco de T2 a T4. A variávelfgi_voldiminui de T1 a T3 e aumenta de T3 a T4. A variávelvoldiminui de T1 a T2 e aumenta de T2 a T4. A variávelmomdiminui de T1 a T2, aumenta de T2 a T3, e diminui de T3 a T4. - Normal (H30): A variável
dd_durdiminui de T1 a T2 e aumenta de T2 a T4. A variávelautocorraumenta de T1 a T2, diminui de T2 a T3, e aumenta muito de T3 a T4, comparada às demais. A variávelvolsegue estável de T1 a T2, aumenta de T2 a T3, e diminui pouco de T3 a T4 (comparada às demais). A variávelfgi_voldiminui de T1 a T2 e aumenta de T2 a T4. A variávelmomaumenta de T1 a T3 e segue estável de T3 a T4. - Fuzzy (H1): A variável
macrodiminui de T1 a T3 e aumenta de T3 a T4. A variávelacaumenta de T1 a T3, aumenta muito de T3 a T4 (comparada às demais). A variávelstressaumenta de T1 a T3 e diminui de T3 a T4. A variávelvolaumenta de T1 a T3, diminui pouco de T3 a T4. A variáveltrenddiminui de T1 a T2, aumenta de T2 a T3, e diminui de T3 a T4. - Fuzzy (H7): A variável
acaumenta de T1 a T2, diminui de T2 a T3, e aumenta muito de T3 a T4, em comparação às outras variáveis especialmente nessa última janela. A variávelmacrodiminui de T1 a T3 e aumenta de T3 a T4. A variáveltrendaumenta de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. A variávelstressaumenta de T1 a T4. A variávelmomaumenta de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. - Fuzzy (H30): A variável
volaumenta de T1 a T4. A variávelacaumenta de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. A variávelmacrodiminui pouco de T1 a T3, quando comparada às demais, e aumenta de T3 a T4. A variávelstressdiminui muito de T1 a T2, e segue diminuindo até T4. A variáveltrendsegue estável de T1 a T4, subindo relativamente pouco de T2 a T3, analisando a janela como um todo.
- Normal (H1): A variável
-
ETH:
- Normal (H1): A variável
dd_durdiminui de T1 a T2, segue estável de T2 a T3, e diminui muito de T3 a T4, quando comparada às demais nessa última janela. A variávelautocorraumenta muito de T1 a T2 (comparada às demais), e diminui de T2 a T4. A variávelmomdiminui de T1 a T2 e aumenta de T2 a T4. A variávelvolaumenta de T1 a T4. A variávelfgi_voldiminui de T1 a T2 e aumenta de T2 a T4. - Normal (H7): A variável
volaumenta de T1 a T2, diminui muito de T2 a T4, comparado-se às demais nessa janela, de T3 a T4. A variáveldd_duraumenta de T1 a T3 e diminui de T3 a T4. A variávelfgi_volaumenta de T1 a T2, diminui de T2 a T3, e aumenta muito de T3 a T4. A variávelautocorraumenta de T1 a T2 e diminui de T2 a T4. A variávelmomdiminui muito de T1 a T2, comparado às demais nessa janela, aumenta de T2 a T3, e diminui novamente de T3 a T4. - Normal (H30): A variável
autocorraumenta de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. A variáveldd_duraumenta de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. A variávelvolaumenta de T1 a T3 e diminui de T3 a T4. A variávelfgi_volaumenta de T1 a T4, de forma mais acentuada em T3 a T4. A variávelmomdiminui de T1 a T2 e aumenta de T2 a T4. - Fuzzy (H1): A variável
macrodiminui de T1 a T2, aumenta pouco de T2 a T3 (comparada às demais), e diminui de T3 a T4. A variávelvolaumenta de T1 a T2, diminui muito de T2 a T3, e diminui de T3 a T4. A variávelacaumenta de T1 a T2 e diminui de T2 a T4. A variávelstressdiminui muito de T1 a T2, comparada às outras variáveis nessa janela, aumenta de T2 a T3, e diminui de T3 a T4. A variáveltrenddiminui de T1 a T2 e aumenta de T2 a T4. - Fuzzy (H7): A variável
macrodiminui de T1 a T3 e a variávelvolaumenta de T1 a T2, com comparação às demais na janela T2/T3, e diminui de T3 a T4. A variávelacdiminui de T1 a T4. A variávelstressdiminui de T1 a T4, sendo destacado em T1 a T2, e aumenta de T2 a T4. A variáveltrenddiminui de T1 a T2 e aumenta de T2 a T4. - Fuzzy (H30): A variável
acdiminui de T1 a T3 e aumenta de T3 a T4. A variávelmacrodiminui de T1 a T3 e aumenta de T3 a T4. A variávelstressdiminui muito (comparada às demais) de T1 a T2 e aumenta de T2 a T4. A variávelvolaumenta de T1 a T2, diminui de T2 a T3, e se
- Normal (H1): A variável
-
LINK:
- Normal (H1): A variável
dd_duraumenta de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. A variávelfgi_volaumenta de T1 a T2, diminui pouco de T2 a T3, quando comparada às demais, e aumenta de T3 a T4. A variávelmomsegue estável de T1 a T3 e diminui de T3 a T4. As variáveisvoleautocorrseguem flutuações de importância semelhantes, diminuem de T1 a T2, aumentam de T2 a T3, e diminuem de T3 a T4. - Normal (H7): A variável
dd_duraumenta de T1 a T2, diminui muito de T2 a T3, e aumenta de T3 a T4. A variávelfgi_voldiminui muito de T1 a T2, comparada às demais nessa janela, aumenta de T2 a T3, e diminui de T3 a T4. A variávelmomaumenta de T1 a T2 e diminui de T2 a T4. A variávelvolaumenta de T2 a T4. A variávelautocorrdiminui de T1 a T2, diminui de T2 a T4. A variávelvolsegue estável de T1 a T2, aumenta de T2 a T3, e diminui de T3 a T4. - Normal (H30): A variável
dd_duraumenta muito de T1 a T2, comparada às demais, diminui de T2 a T3, e aumenta de T3 a T4. A variávelautocorrdiminui de T1 a T2, e diminui de T2 a T3, e aumenta de T3 a T4. A variávelfgi_voldiminui muito de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. A variávelvolaumenta de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. A variávelmomdiminui de T1 a T2, aumenta de T2 a T3, e diminui de T3 a T4. - Fuzzy (H1): A variável
stressdiminui de T1 a T2, quando comparada às demais variáveis nessa janela, de T2 a T3, e diminui de T3 a T4. A variávelmacrodiminui de T1 a T4. A variávelacaumenta de T1 a T2 e diminui de T2 a T4. A variávelvolaumenta de T1 a T3 e diminui de T3 a T4. A variáveltrendsegue estável de T1 a T2 e aumenta de T2 a T4. - Fuzzy (H7): A variável
stressdiminui de T1 a T2, aumenta muito, quando a comparamos às demais variáveis nessa janela, de T2 a T3, e diminui de T3 a T4. A variávelacdiminui de T1 a T2 e aumenta de T2 a T4. A variávelvoldiminui muito de T1 a T2, aumenta de T2 a T3, e se mantém estável de T3 a T4. A variávelmacrodiminui de T1 a T2 e aumenta de T2 a T4. A variáveltrenddiminui de T1 a T2 e aumenta de T2 a T4. - Fuzzy (H30): A variável
stressdiminui pouco de T1 a T3, comparada às demais, especialmente na janela de T1 a T2, diminui de T3 a T4. A variávelacdiminui muito de T1 a T2, diminui de T2 a T3, e aumenta pouco de T3 a T4. A variávelvolsegue estável de T1 a T2, mantém-se estável de T2 a T3, e diminui pouco de T3 a T4. A variávelmacroaumenta de T1 a T2 e diminui de T2 a T4. A variáveltrenddiminui pouco de T1 a T3 e aumenta pouco de T3 a T4, quando a comparamos às demais.
- Normal (H1): A variável
-
SOL:
- Normal (H1): A variável
volaumenta de T1 a T2 e diminui de T2 a T4, com diminuição escassa, comparada às demais (em T2/T3), e grande. A variávelfgi_voldiminui muito de T1 a T2 (comparada às demais), pouco de T2 a T3, e aumenta de T3 a T4. A variáveldd_durdiminui muito de T1 a T2, pouco de T2 a T3, e continua a diminuir de T3 a T4. A variávelmomdiminui de T1 a T2, aumenta de T2 a T3, e continua estável de T3 a T4. A variávelautocorrdiminui de T1 a T2, aumenta de T2 a T3, e diminui de T3 a T4. - Normal (H7): A variável
fgi_voldiminui muito, em comparação às outras variáveis, de T1 a T2, e aumenta de T2 a T4. A variáveldd_durdiminui de T1 a T2, aumenta de T2 a T3, diminui de T3 a T4, e varia pouco de T1 a T2, aumentando de T2 a T4. A variávelvolaumenta de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. A variávelautocorrdiminui pouco ao longo das três janelas. - Normal (H30): A variável
dd_duraumenta muito de T1 a T4, quando a comparamos às demais. A variávelfgi_voldiminui de T1 a T2 e aumenta de T2 a T4. A variáveltrendaumenta pouco de T2 a T3, e novamente diminui de T3 a T4. A variávelvolaumenta de T1 a T2, diminui de T2 a T4. A variávelmomse mantém estável de T1 a T3 e diminui pouco, comparado ao restante do gráfico, de T3 a T4. - Fuzzy (H1): A variável
macrodiminui muito de T1 a T2, segue estável de T2 a T3 e aumenta muito de T3 a T4. A variávelvoldiminui de T1 a T4. A variávelacaumenta de T1 a T3 e diminui de T3 a T4. A variáveltrendaumenta de T1 a T3 e diminui de T3 a T4. A variávelstressaumenta de T1 a T3 e diminui de T3 a T4. - Fuzzy (H7): A variável
macroaumenta de T1 a T2, diminui de T2 a T3 e aumenta de T3 a T4. A variávelstress, em comparação às demais, aumenta muito de T1 a T2, se mantém estável de T2 a T3, e diminui de T3 a T4. A variávelacaumenta de T1 a T2, se mantém estável de T2 a T3, e aumenta de T3 a T4. A variávelvolaumenta muito de T1 a T2, diminui muito de T2 a T3, e segue estável de T3 a T4. A variáveltrendaumenta muito de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. - Fuzzy (H30): A variável
stresspermanece estável de T1 a T2 e aumenta de T2 a T4. A variávelmacroaumenta de T1 a T2, permanece estável de T2 a T3, e aumenta de T3 a T4. A variávelvolaumenta de T1 a T2, diminui de T2 a T3, e permanece estável de T3 a T4. A variávelacdiminui de T1 a T2, permanece estável de T2 a T3, e diminui de T3 a T4. A variáveltrendpermanece estável, com um aumento de importância que é pequeno quando comparado às outras.
- Normal (H1): A variável
-
XRP:
- Normal (H1): A variável
autocorr_30dapresenta dois decréscimos sucessivos de T1 para T2 e de T2 para T3, porém de T3 para T4 alcança um valor de importância superior ao início de T1. A variávelvov_60dapresenta uma leve subida de T1 para T2 e outro mais brusca de T2 para T3, porém uma queda de T3 a T4 e retorna aos níveis do início de T1. A variávelmom_7dsofre um processo de queda do T1 para T2, um crescimento leve aumento de T2 para T3 e uma elevação de importância muito expressiva do T3 a T4.fgi_vol_30dsofre aumento de T1 a T3 e queda de T3 para T4 passando do seu valor inicial de T1. - Normal (H7): A variável
autocorrdiminui de T1 a T3 e aumenta de T3 a T4. A variávelfgi_voldiminui de T1 a T3, com diminuição maior de T1 a T2, e aumenta de T3 a T4. A variáveldd_durdiminui muito, em comparação às demais variáveis, de T1 a T2, aumenta muito de T2 a T3, e diminui novamente de T3 a T4. A variávelvoldiminui de T1 a T2 e segue estável de T2 a T4. A variávelmomdiminui de T1 a T3 e aumenta de T3 a T4. - Normal (H30): A variável
fgi_volaumenta de T1 a T2, diminui de T2 a T3 e aumenta muito de T3 a T4 (comparada às demais). A variáveldd_durdiminui de T1 a T2, aumenta de T2 a T3, e segue estável de T3 a T4. A variávelvoldiminui muito de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. A variávelmomaumenta de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. A variávelautocorrdiminui muito de T1 a T2 e aumenta de T2 a T4. - Fuzzy (H1): A variável
stressaumenta muito de T1 a T4, com especial ênfase na subida de T3 a T4, onde o aumento é mais acentuado que das demais variáveis. A variávelvolaumenta de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. A variávelacaumenta de T1 a T2, diminui de T2 a T3, e aumenta de T3 a T4. A variávelmacrodiminui de T1 a T3 e aumenta de T3 a T4. A variáveltrenddiminui de T1 a T2, aumenta de T2 a T3, e diminui de T3 a T4. - Fuzzy (H7): A variável
macroaumenta de T1 a T2, diminui muito de T2 a T3 (quando comparadas às demais) e aumenta de T3 a T4. A variávelstressaumenta muito de T1 a T2, diminui de T2 a T3 e aumenta de T3 a T4. A variávelacdiminui de T1 a T2, aumenta de T2 a T3 e diminui de T3 a T4. A variávelvoldiminui de T1 a T2, aumenta de T2 a T3 e segue estável de T3 a T4. A variáveltrenddiminui de T1 a T2 e segue estável de T2 a T4. - Fuzzy (H30): A variável
stressdiminui de T1 a T2, aumenta de T2 a T3 e diminui de T3 a T4. A variávelmacroaumenta de T1 a T2, diminui de T2 a T3 e aumenta de T3 a T4. A variávelvoldiminui muito (quando comparadas à mudança das demais variáveis) em T1/T2, aumenta pouco de T2 a T3, e diminui de T3 a T4. A variávelacdiminui de T1 a T2, aumenta de T2 a T3 e segue estável de T3 a T4. A variáveltrendsegue estável de T1 a T4 e próxima de 0.
- Normal (H1): A variável
10. Discussão e análises
10.1 Onde a fuzzificação ajuda ou atrapalha
Onde ajudou: No agregado, a fuzzificação ajudou principalmente por forçar o modelo a “assumir posição” com mais frequência, em vez de ficar concentrado na classe intermediária. Na prática, o modelo fuzzy ficou menos “neutro” e um pouco mais direcional, o que tende a ser positivo quando o objetivo é capturar regimes de retorno mais claros (principalmente movimentos de alta). Isso aparece no comportamento geral das previsões: comparado ao modelo contínuo, o fuzzy aumenta a capacidade de apontar movimentos extremos (em especial alta), em vez de jogar grande parte dos casos para o “meio do caminho”.
Além disso, por trabalhar com graus de pertencimento (e não apenas valores brutos), a fuzzificação pode ter ajudado em um ponto bem simples: reduzir a sensibilidade a pequenas variações que não mudam “o regime” de fato. Ou seja, ela pode ser melhor para representar situações qualitativas (“tendência de alta”, “mercado calmo”, “stress alto”), que são exatamente o tipo de linguagem que o projeto tenta capturar.
Onde atrapalhou: O lado negativo é que esse ganho de “direcionalidade” veio com um custo: o fuzzy ficou mais propenso a errar na direção errada quando o mercado estava em queda. Em outras palavras, ao tentar ser menos neutro, ele corre mais risco de classificar como “alta” cenários que eram “queda” e esse tipo de erro é economicamente mais perigoso, porque, numa estratégia de sinal, isso costuma virar posição comprada em um dia ruim. Esse padrão aparece de forma agregada na matriz de confusão: o modelo fuzzy aumentou acertos na classe de alta, mas também aumentou erros relevantes quando a classe real era queda.
Outro ponto: quando a fuzzificação não está muito bem calibrada para cada tipo de variável (isto é, quando se usa uma estrutura “genérica” para tudo), ela pode perder informação que é útil nos dados contínuos, principalmente nuances que ajudam o modelo a diferenciar casos parecidos dentro da classe intermediária. Então, em vez de refinar, a fuzzificação pode “achatá-los” demais.
No total, a fuzzificação não foi um upgrade claro em performance geral: ela ajudou quando o benefício era ter um modelo mais “corajoso” em identificar regimes e capturar alta, mas atrapalhou ao aumentar o risco de erros com direção errada em cenários de queda, o que piora a qualidade econômica do sinal. Em resumo: o fuzzy parece trocar parte da “prudência neutra” do contínuo por mais direcionalidade e isso só vale a pena se o projeto controlar esses erros críticos (especialmente de queda para alta).
10.2 Limitações do estudo
A primeira limitação é de dados e recorte amostral. O estudo usa séries diárias (OHLCV) e proxies macro/sentimento (como FGI), com janela histórica descrita como cerca de cinco anos (2021–hoje) e fontes como Binance e Yahoo Finance. Em cripto, isso é um período com mudanças estruturais relevantes (ciclos de liquidez, choques de volatilidade e fases de “risk-on/risk-off”), então existe risco de mudança de regime que o modelo não consegue generalizar bem: padrões de treino podem não se repetir no teste, especialmente em horizontes curtos onde o ruído domina.
A segunda limitação é metodológica: (i) risco de viés de sobrevivência e de “universo móvel” se o Top 10 for definido olhando para o presente; o próprio planejamento do projeto aponta a necessidade de uma data de corte reproduzível para definir o Top 10 e lidar com mudanças de ticker e trechos de baixa liquidez, justamente para evitar distorções desse tipo. (ii) a fuzzificação depende de escolhas de desenho (funções de pertinência e partições), que são parcialmente arbitrárias: a primeira tentativa, por exemplo, usou uma zona intermediária trapezoidal mais larga (neutralidade) e extremos “pontudos” (triangulares), mas essa padronização “igual para tudo” mostrou limitações porque as features têm distribuições e significados diferentes. Por fim, as métricas avaliadas (F1 macro, acurácia, Log Loss e confusão) medem qualidade estatística, mas não substituem uma avaliação econômica completa (custos de transação, risco de drawdown e assimetria de perdas).
10.3 Sugestões de extensão
Uma extensão natural é ampliar o desenho experimental para testar mais horizontes (ex.: 2–3 dias, 14 dias, 60/90 dias) e também variações de discretização do alvo, porque a utilidade da fuzzificação parece ser condicional ao ativo e ao horizonte (ganhos pontuais, não sistemáticos). Além disso, vale transformar a comparação em um critério de decisão prático: por exemplo, usar fuzzy apenas onde ele melhora calibração (Log Loss) ou reduz erros críticos, já que vimos casos de vantagem clara (ex.: LINK) e casos de desvantagem consistente (ex.: ETH). Outra extensão é atacar diretamente o que os resultados sugerem: o fuzzy aumenta a direcionalidade, mas pode gerar “otimismo” em quedas (erro de comissão).
Para isso, três caminhos são fortes: (i) FCM estável (Fuzzy C-Means) com janelas móveis e mecanismos de estabilidade (ex.: inicialização consistente, penalização de troca de cluster, ou “anchor points”) para reduzir a sensibilidade do regime fuzzy a ruído; (ii) regras de regime/filtragem (ex.: exigir confirmação por volatilidade/stress antes de aceitar “Alta”, ou suavizar transições com lógica de persistência), reduzindo falsos positivos de alta em queda; e (iii) fechar o ciclo econômico com backtest, convertendo classes em sinais e avaliando retorno e risco com custos (slippage/fees), como já estava previsto no escopo do projeto, para julgar se o ganho de “capturar extremos” compensa o risco de errar na direção errada.
11. Conclusão
Este trabalho investigou se a fuzzyficação de features, em comparação com variáveis contínuas, poderia representar melhor regimes de mercado e aumentar a previsibilidade de retornos t+1 em criptoativos em um modelo supervisionado. A construção do estudo mostrou que o principal desafio não foi apenas “criar muitas variáveis”, mas garantir que elas fossem complementares: a engenharia inicial enfrentou alta redundância e correlação, exigindo uma seleção disciplinada e a expansão do universo de features até chegar a um conjunto final mais consistente, com baixa sobreposição e melhor cobertura dos regimes econômicos definidos. Na etapa de fuzzificação, a comparação evidenciou um trade-off: no agregado, o modelo fuzzy tende a ser mais “direcional” e menos neutro, o que pode ajudar a capturar movimentos de alta e mudanças de regime mais claras; por outro lado, esse ganho vem acompanhado de maior risco de erros com direção errada em cenários adversos (especialmente queda classificada como alta), o que reduz a qualidade econômica do sinal. Assim, a fuzzificação não se mostrou um upgrade universal em performance total, mas sim uma abordagem promissora quando bem calibrada por tipo de feature e usada como ferramenta de robustez e interpretação de regimes, deixando como principal conclusão que, para cripto, a consistência do pipeline (seleção por correlação + diversidade econômica + fuzzificação adequada) importa mais do que a escolha isolada entre “contínuo” e “fuzzy”.